Unary call sites and intention-revealing interfaces
Matthias Noback
Call sites
One of the features I love most about my IDE is the button “Find Usages”. It is invaluable when improving a legacy code base. When used on a class it will show you where this class is used (as a parameter type, in an import statement, etc.). When used on a method, it will show you where this method gets called. Users of a method are often called “clients”, but when we use “Find Usages”, we might as well use the more generic term “call sites”.
I first saw that term used by Michael Feathers in his blog post “Unary Call Sites and Architecture”. He proposes it as a way of analyzing code quality and architectural style. When a method is used in only one place, it is said to have a “unary call site”. Michael says about these unary call sites:
There’s a code base developed by a friend that is 45% methods with single call sites. He and his team are very zealous about their design so I’m not surprised and I am going to investigate further.
I’m curious where his investigations are leading to, since I often come to the same conclusion: when methods are made with a single purpose, they tend to be better methods. Some reasons for this are:
- The method name can be very specific; it will clearly describe its use case. The reader of the code will have no trouble understanding how its used, and what the implications of calling it are.
- The method won’t need to tailor a diverse range of clients, so it won’t have a lot of code and branches dealing with exotic scenarios, edge cases, etc.
Reusing methods for different use cases leads to everything that’s forbidden by clean code literature. For example, adding flags to a method to allow different usages:
🔥 Have a function that gets used in about 100 places that you need to behave slightly differently for some new code? Add an optional flag. pic.twitter.com/YzWVNErQlU
— Legacy Coder (@legacy_coder) June 28, 2017
Adventures in legacy code
It’s only appropriate to quote Twitter’s @legacy_coder here, since legacy projects tend to have big issues with call sites. I must be honest with you: this includes the legacy projects created today. Older projects may be worse though. Maintainers of legacy projects tend to reuse and adapt existing methods. This allows them to do “minimal” work in order to fix a bug or add a small feature. But new projects have the same issue. Developers will create all these generic and reusable sub-frameworks for their convenience. This code will have multiple call sites, which will make it harder to adopt the code to new requirements. (Last week a former co-worker showed me a nice example of such overly generic code I wrote a couple of years ago…)
What’s so bad about multiple call sites? Well, as always, the Stable Dependencies Principle kicks in. Something that’s used (i.e. depended upon) in many places, should be stable (i.e. it should very rarely change). The principle works in two ways:
- We don’t want it to change (since that would break the code in all the call sites).
- It can’t easily change (since it would cost us a lot of time to update the client code in all the call sites).
If we start reusing methods, they will over time become ever more difficult to change. When the point has come that we are terribly annoyed by the bad quality of these methods, it will be almost impossible to do anything about it. I think you will recognize this pain, when you want to get rid of that ugly table gateway or utility class and you find out that it has 100+ call sites…
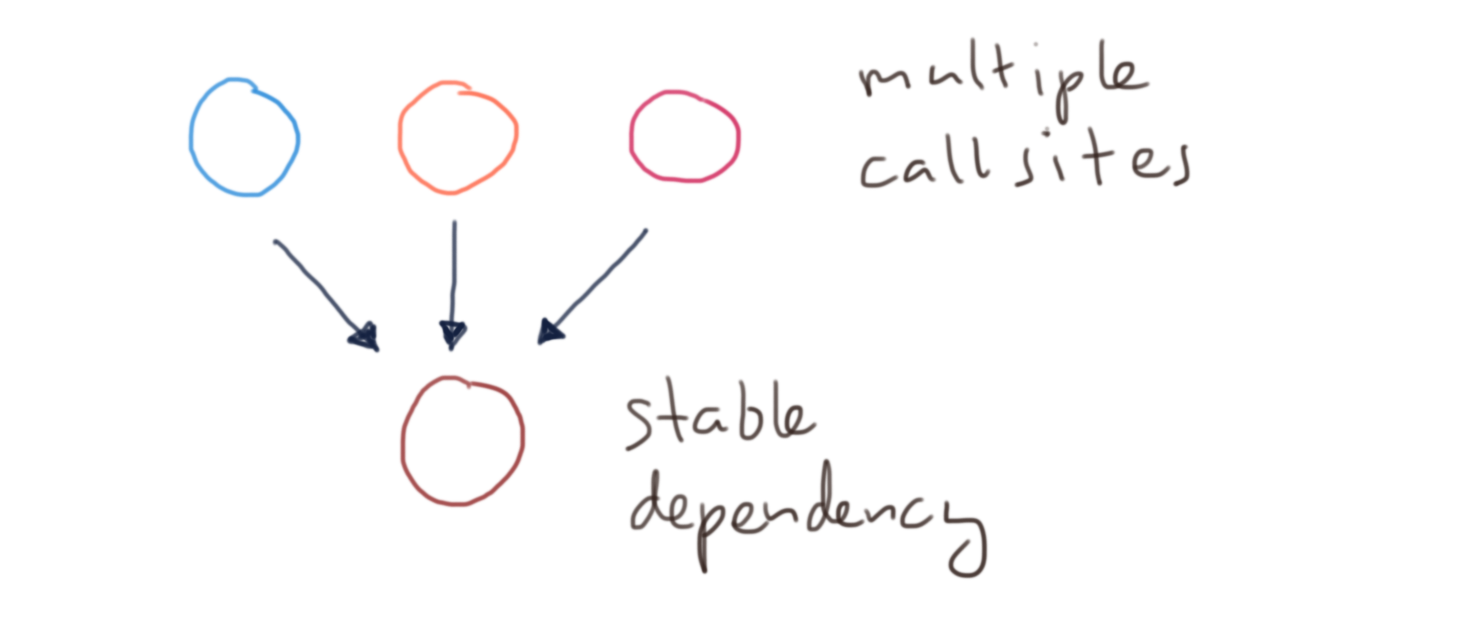
Reducing the number of call sites
What can you do to reduce the number of call sites for a method? There are several techniques available.
Dependency inversion
Interfaces tend to be more stable than classes, mainly because they are more abstract than classes. So if a method has many clients, you might start by introducing an interface. You can either let the original class implement the new interface, or you can create a new class which wraps the original class. In other words, you either adapt the class, or adopt the class. An example related to previous discussions on this blog about Doctrine ORM and using its classes in your code:
// the original class every clients depends on:
namespace Framework\ORM {
class EntityRepository
{
public function persist(Object $object);
}
// the newly defined, use case-specific interface:
interface UserRepository
{
public function add(User $user);
}
// the adapter:
class UserORMRepository implements UserRepository
{
public function __construct(EntityRepository $entityRepository)
{
$this->entityRepository = $entityRepository;
}
public function add(User $user)
{
$this->entityRepository->persist($user);
}
}
Once you update all the clients to use the UserRepository interface instead of the framework’s EntityRepository class, you’ve successfully applied the Dependency Inversion Principle. You’re now depending on something more abstract than the original class. You have also successfully reduced the number of call sites for EntityRepository::persist(). This will eventually allow you to replace or get rid of the original EntityRepository.
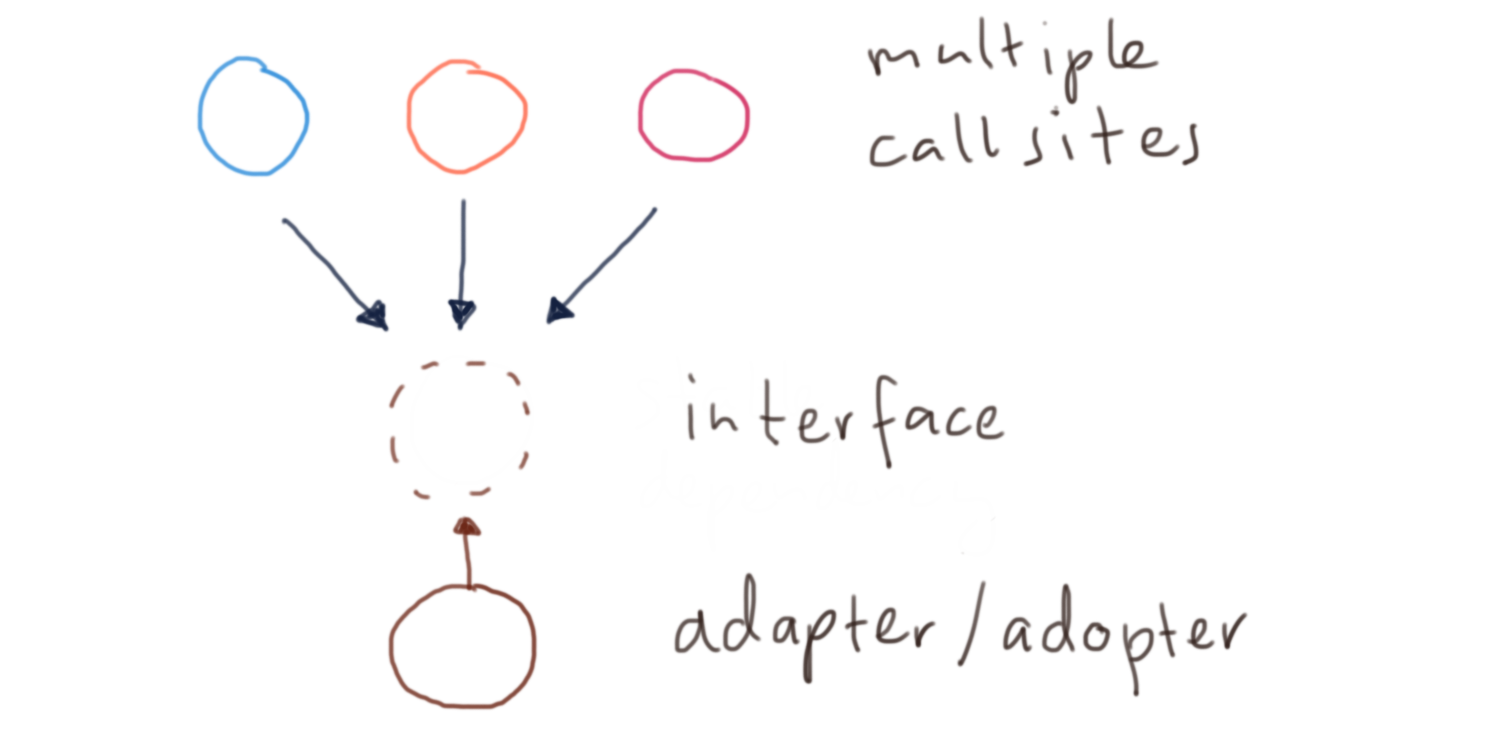
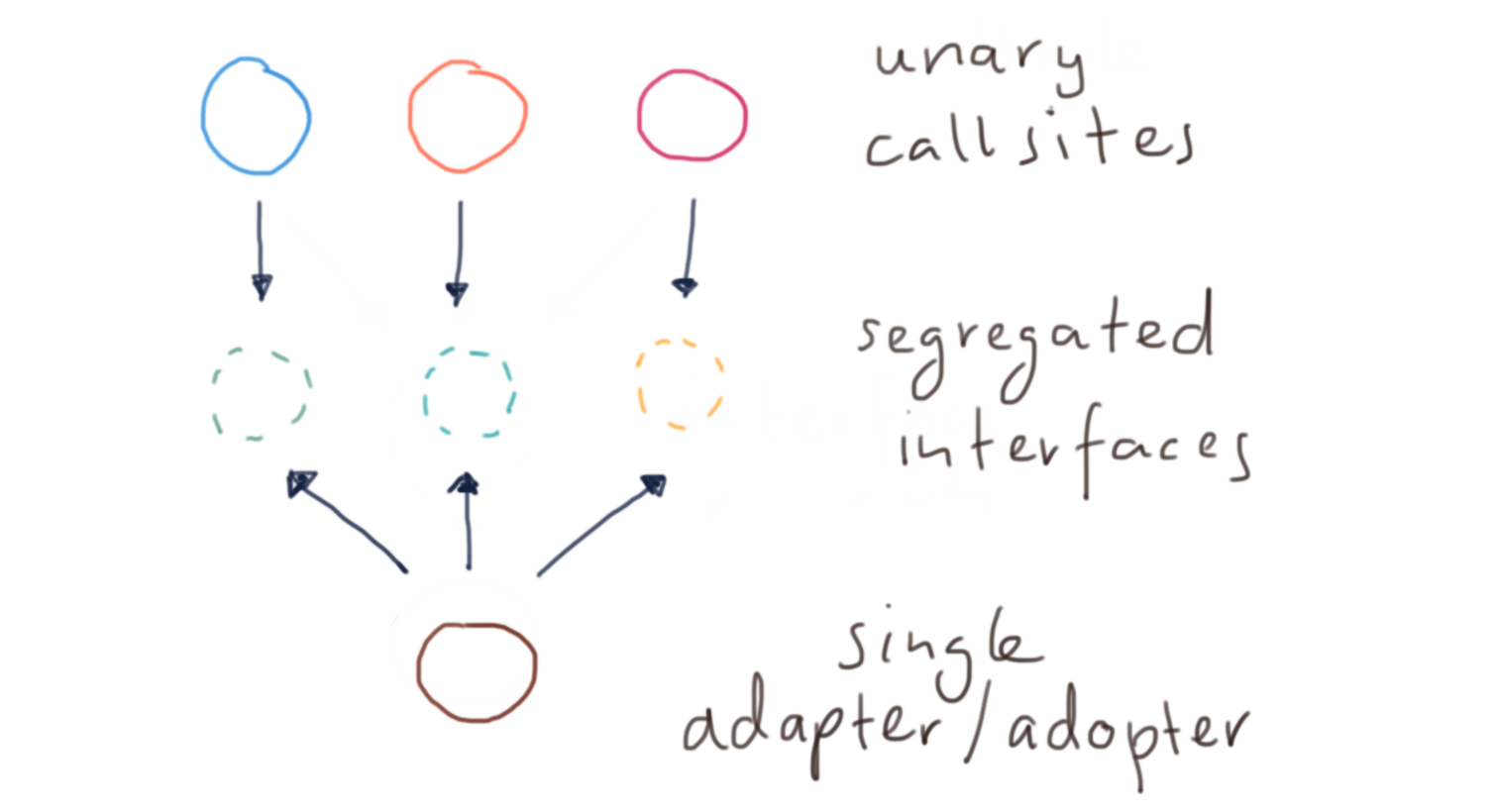
Segregating the interface based on how or where it’s used, will help you reduce the number of call sites even further. This doesn’t mean that you need a new class for every one of those new interfaces. You can always have a single class implementing multiple interfaces. This technique can sometimes be quite useful, in particular to keep low-level details (e.g. SQL column names, protocol details, etc.) in one place. In practice I don’t often find the need for a class to implement multiple interfaces. In fact, such a class quickly becomes too large to be manageable.
Intention-revealing interfaces
Maybe you noticed I sneaked in a bit of “intention-revealing” naming in the above example. So far the existing call sites of EntityRepository::persist() used it only to insert new user records into the database. However, EntityRepository::persist() can do much more. It works for any object it can map to a database table, and it also supports updates (by calculating a change set for the object).
While introducing the custom UserRepository interface, I made the use case for it more specific: we only need to insert a user record into the database, so the interface should only offer a method for that use case. Hence the explicit name add() and the explicit parameter type User.
This is a great improvement for the code: as a reader you won’t have to find out if the code is about adding or updating users. You won’t have to worry about either use case still being supported after a change you make. You only have to think about the use case of adding users. In essence you have reduced the number of ways the code in your project can be used. This will make it easier to replace the underlying storage mechanism completely. And that is a great architectural feature for a project to have.
Another example of intention-revealing interfaces in the realm of the domain model can be found in a previous article: “Simple CQRS - reduce coupling, allow the model(s) to evolve”.
By the way, “intention-revealing interface” isn’t about the language construct interface. It’s about the interface of your objects at large: the methods, their names, and their parameter and return types. By producing intention-revealing interfaces, you will likely reduce the number of call sites. It will prevent reuse of methods, since it will be clear to the programmer who is tempted to reuse the method, that it wasn’t intended for reuse.
We can find generality and flexibility in trying to deliver specific solutions, but if we weigh anchor and forget the specifics too soon, we end up adrift in a sea of nebulous possibilities, a world of tricky configuration options, overloaded and overburdened parameter lists, long-winded interfaces, and not-quite-right abstractions. In pursuit of arbitrary flexibility, you can often lose valuable properties — whether intended or accidental — of alternative, simpler designs.
Kevlin Henney, “Simplicity Before Generality, Use Before Reuse”
Dependency injection
Another technique for reducing the number of call sites is to apply dependency injection. I leave that discussion for another article.