Most recent articles about PHP

New edition for the Rector Book

A couple of weeks ago, Tomas Votruba emailed me saying that he just realized that we hadn’t published an update of the book we wrote together since December 2021. The book I’m talking about is “Rector - The Power of Automated Refactoring”. Two years have passed since we published the current version. Of course, we’re all very busy, but no time for excuses - this is a book about keeping projects up-to-date with almost no effort… We are meant to set an example here!
By Matthias Noback
read moreDealing with technical debt during the sprint
It’s quite ironic that my most “popular” tweet has been posted while Twitter itself is in such a chaotic phase. It’s also quite ironic that I try to provide helpful suggestions for doing a better job as a programmer, yet such a bitter tweet ends up to be so popular.
Twitter and Mastodon are micro-blogging platforms. The problem with micro-blogs, and with short interactions in general, is that everybody can proceed to project onto your words whatever they like. So at some point I often feel the need to explain myself with more words, in an “actual” blog like this one.
By Matthias Noback
read moreRefactoring without tests should be fine
Refactoring without tests should be fine. Why is it not? When could it be safe?
From the cover of “Refactoring” by Martin Fowler:
Refactoring is a controlled technique for improving the design of an existing code base. Its essence is applying a series of small behavior-preserving transformations, each of which “too small to be worth doing”. However the cumulative effect of each of these transformations is quite significant.
By Matthias Noback
read moreMore PHP articles...
Most recent articles about Fortran
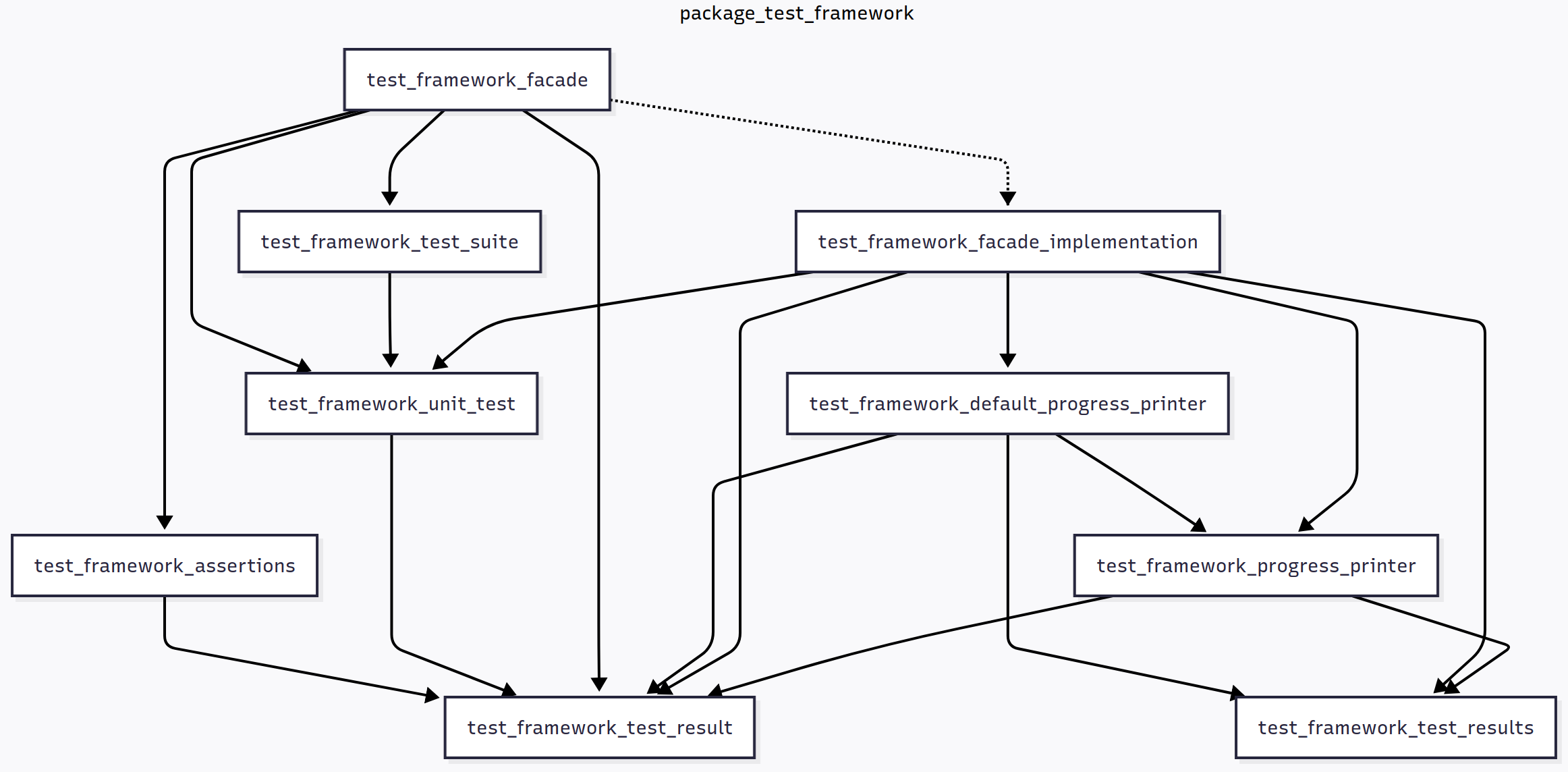
Fortran - Testing - Improving the design of the test framework - Part 2
Several articles later, it turns out the little test framework has grown very fast. We’re looking at around 400 lines of code in a single test_framework module. In my opinion, this requires too much scrolling and jumping through the code to understand what’s going on or make changes. I’m aware “real-world” projects suffer from files that are a lot larger, but they are in a lot of trouble because of it. It’s smart to split large modules into smaller ones at a much earlier stage. As we discussed before, the following guidelines may be used when doing so:
By Matthias Noback
read more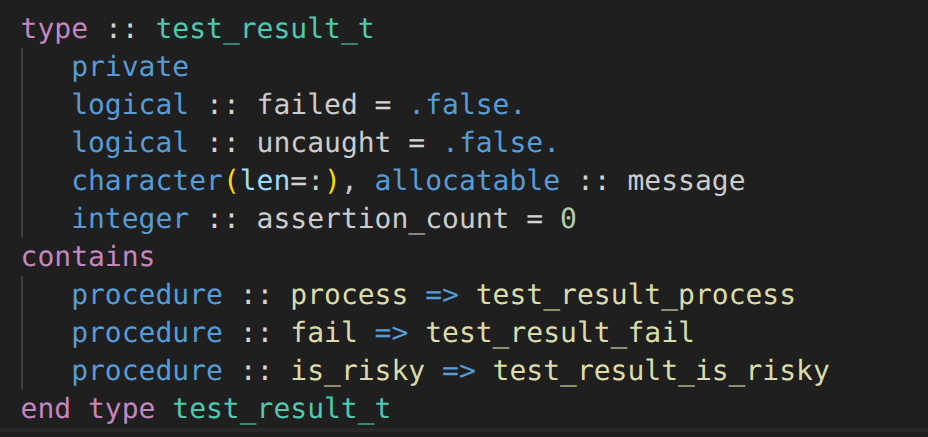
Fortran - Testing - Improving the design of the test framework - Part 1
The right approach to software design, in my opinion, is to work with what you have, build more functionality on top of it, then realizing there are design issues, then fixing those issues by redesigning ad hoc. Where, in my experience, most software design efforts go wrong is:
- We realize there are design issues, yet we don’t fix them. Maybe it’s too scary.
- We fix design issues, but too early, when we can’t yet know if the new design is better. We lack feedback from actual use.
In this article series, I’m happy to report, I haven’t spent too much time designing upfront. But now I want to tackle some issues, that I encountered while adding more tests. Let’s look at one of our tests:
By Matthias Noback
read more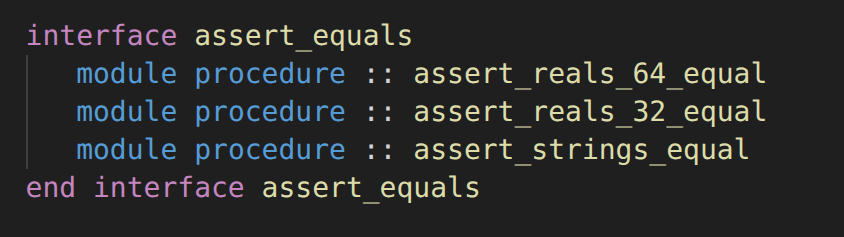
Fortran - Testing - More assertion functions
When expanding our test suite, we’ll certainly encounter the need for an assert_equals function that works with other types than real(kind=real64). We’d want to compare values of type logical, character, integer, etc. For example, say we have a utility function str_to_upper for which we are adding a unit-test in the test_string module. This function is supposed to convert the letters in a string to their uppercase alternative. The test looks like this:
By Matthias Noback
read moreMore Fortran articles...