Keep an eye on the churn; finding legacy code monsters
Matthias Noback
Setting the stage: Code complexity
Code complexity often gets measured by calculating the Cyclomatic Complexity per unit of code. The number can be calculated by taking all the branches of the code into consideration.
Code complexity is an indicator for several things:
- How hard it is to understand a piece of code; a high number indicates many branches in the code. When reading the code, a programmer has to keep track of all those branches, in order to understand all the different ways in which the code can work.
- How hard it is to test that piece of code; a high number indicates many branches in the code, and in order to fully test the piece of code, all those branches need to be covered separately.
In both cases, high code complexity is a really bad thing. So, in general, we always strive for low code complexity. Unfortunately, many projects that you’ll inherit (“legacy projects”), will contain code that has high code complexity, and no tests. A common hypothesis is that a high code complexity arises from a lack of tests. At the same time, it’s really hard to write tests for code with high complexity, so this is a situation that is really hard to get out.
If you’re curious about cyclometic complexity for your PHP project, phploc gives you a nice summary, e.g.
Complexity
Cyclomatic Complexity / LLOC 0.30
Cyclomatic Complexity / Number of Methods 3.03
Setting the stage: Churn
Code complexity doesn’t always have to be a big problem. If a class has high code complexity, but you never have to touch it, there’s no problem at all. Just leave it there. It works, you just don’t touch it. Of course it’s not ideal; you’d like to feel free to touch any code in your code base. But since you don’t have to, there’s no real maintainability issue. This bad class doesn’t cost you much.
What’s really dangerous for a project is when a class with a high code complexity often needs to be modified. Every change will be dangerous. There are no tests, so there’s no safety net against regressions. Having no tests, also means that the behavior of the class hasn’t been specified anywhere. This makes it hard to guess if a piece of weird code is “a bug or a feature”. Some client of this code may be relying on the behavior. In short, it will be dangerous to modify things, and really hard to fix things. That means, touching this class is costly. It takes you hours to read the code, figure out the right places to make the change, verify that the application didn’t break in unexpected ways, etc.
Michael Feathers introduced the word “churn” for change rate of files in a project. Churn gets its own number, just like code complexity. Given the assumption that each class is defined in its own file, and that every time a class changes, you create a new commit for it in your version control software, a convenient way to quantify “churn” for a class would be to simply count the number of commits that touch the file containing it.
Thinking about version control: there is much more valuable information that you could derive from your project’s history. Take a look at the book “Your Code as a Crime Scene” by Adam Tornhill for more ideas and suggestions.
Code insight
Combining these two metrics, code complexity and churn, we could get some interesting insights about our code base. We could easily spot the classes/files which often need to be modified, but are also very hard to modify, because they have a high code complexity. Since the metrics themselves are very easy to calculate (there’s tooling for both), it should be easy to do this.
Since tooling would have to be specific for the programming language and version control system used, I can’t point you to something that always works, but for PHP and Git, there’s churn-php. You can install it as a Composer dependency in your project, or run it in a Docker container. It will show you a table of classes with high churn and high complexity, e.g.
+-----------------------+---------------+------------+-------+
| File | Times Changed | Complexity | Score |
+-----------------------+---------------+------------+-------+
| src/Core/User.php | 355 | 875 | 1 |
| src/Sales/Invoice.php | 235 | 274 | 0.234 |
+-----------------------+---------------+------------+-------+
“Times Changed” represents the value calculated for “churn”, and “Complexity” is the calculated code complexity for that file. The score is something I came up with; it is the normalized distance from the line which represents “it’s okay”.
Plotting these classes in a graph, it would look something like this:
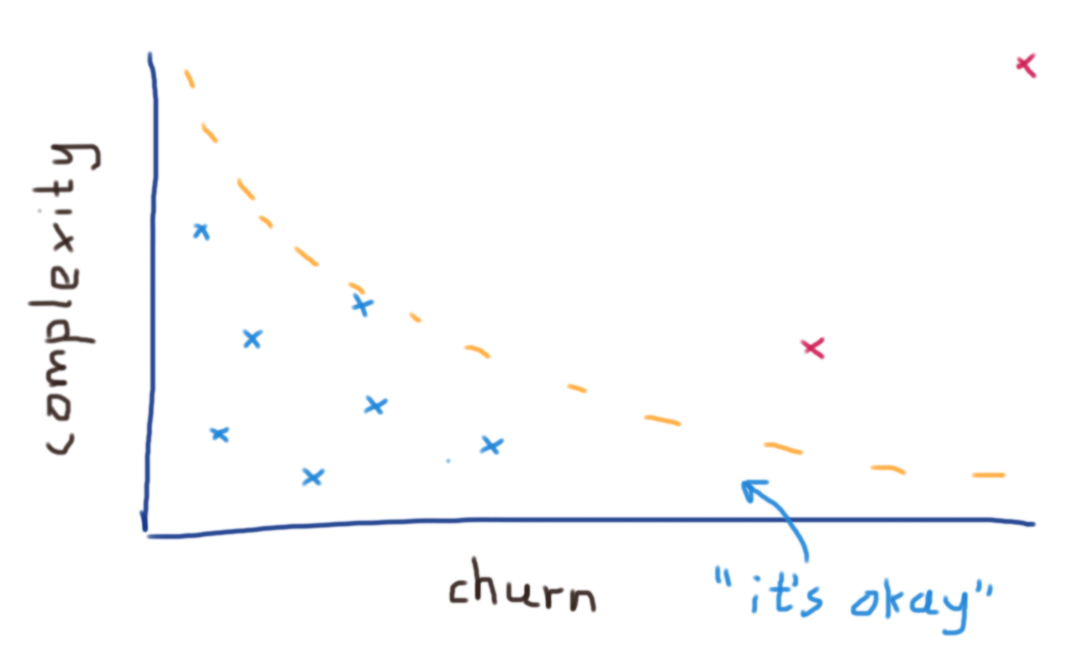
“It’s okay”
What does that mean, “it’s okay”? Well, we can always deal with a certain level of complexity, given a certain change rate. If it isn’t too painful to make a change to a class, even though it needs refactoring, the refactoring effort itself will cost us more than it will save you in terms of future programming efforts. You can always improve code, but since you as a programmer are expensive too, you should always ask yourself what the benefits really are.
Beneath the line are classes that are simple classes that change often (no problem), or medium complex classes that rarely change (no problem). Only when a class is above the line, closer to the top right corner of the graph, we should admit that it’s no longer “okay”.
Hypotheses, observations, advise
Besides the fact that it’s cool to run the tool and find out which classes are dangerous legacy monsters, there are some more profound things about the nature of software development to consider here.
First, let me tell you my hypothesis: if you’ve known the project for a while, you don’t need to run the tool to be able to tell me which classes are the bad ones. (Please let me know if this is/was the case for you!).
Then, I suggest you also read Sandi Metz’ article “Breaking up the behemoth” on this topic. Sandi suspects that these “unwanted outliers” are way larger than other classes, but also represent core concepts in the domain. This was initially quite surprising to me. If a class represents a core domain concept, I’d assume you don’t let it end up with such poor code quality. But it makes sense. As desired behavior becomes more clear, as the team gains deeper insights in the domain, related classes need to be modified as well. But as you know, change over time requires a reconsideration of the larger design, which may not always actually take place. Meanwhile these central classes become more and more depended upon, which makes them harder to change without breaking all their clients.
Talk with your team to figure out how to fight your legacy monsters. Involve management as well, and explain to them how defeating them will make you work faster in the near future. How to do it? As Sandi puts it in the above-mentioned article:
A 5,000 line class exerts a gravitational pull that makes it hard to imagine creating a set of 10 line helper classes to meet a new requirement. Make new classes anyway. The way to get the outliers back on the green line where they belong is to resist putting more code in objects that are already too large. Make small objects, and over time, the big ones will disappear.