Book excerpt - Decoupling from infrastructure, Conclusion
Matthias Noback
This article is an excerpt from my book Advanced Web Application Architecture. It contains a couple of sections from the conclusion of Part I: Decoupling from infrastructure.

This chapter covers:
- A deeper discussion on the distinction between core and infrastructure code
- A summary of the strategy for pushing infrastructure to the sides
- A recommendation for using a domain- and test-first approach to software development
- A closer look at the concept of “pure” object-oriented programming
Core code and infrastructure code
In Chapter 1 we’ve looked at definitions for the terms core code and infrastructure code. What I personally find useful about these definitions is that you can look at a piece of code and find out if the definitions apply to it. You can then decide if it’s either core or infrastructure code. But there are other ways of applying these terms to software. One way is to consider the bigger picture of the application and its interactions with actors. You’ll find the term actor in books about user stories and use cases by authors like Ivar Jacobson and Alistair Cockburn, who make a distinction between:
- Primary actors, which act upon our system
- Secondary or supporting actors, upon which our system acts
As an example, a primary actor could be a person using their web
browser to send an HTTP POST request to our application. A
supporting actor could be the relational database that our application
sends an SQL INSERT query to. Communicating with both actors requires
many infrastructural elements to be in place. The web server should be
up an running, and it should be accessible from the internet. The server
needs to pass incoming requests to the application, which likely uses a
web framework to process the HTTP messages and dispatch them to the
right controllers. On the other end of the application some data may
have to be stored in the database. PHP needs to have a PDO driver
installed before it can connect to and communicate with the database.
Most likely you’ll need a lot of supporting code as well to do the
mapping from domain objects to database records. All of the code
involved in this process, including a lot of third-party libraries and
frameworks, as well as software that isn’t maintained by yourself (like
the web server), should be considered infrastructure code.
Most of the time between the primary actor sending an HTTP request to your server, and the database storing the modified data, will be spent by running infrastructure code and most of this code can be found in PHP extensions, frameworks, and libraries. But somewhere between ingoing and outgoing communication the server will call some of your own code, the so-called user code.
User code is what makes your application special: what things can you do with your application? You can order an e-book. You can pay for it. What kind of things can you learn from your application? You can see what e-books are available. And once you’ve bought one, you can download it. Frameworks, libraries, and PHP extensions could never help you with this kind of code, because it’s domain-specific: it’s your business logic.
The following figure shows that user code is in the middle of a lot of infrastructure code:

Even if we try to ignore most of the surrounding infrastructure while working on and testing user code, we’ll often find that this code is hard to work with. That’s because the code still contains many infrastructural details. A use case may be inseparable from the web controller that invokes it. The use of service locators and the likes prevents code from running in isolation, or in a different context. Calls to external services require the external service to be available when we want to locally test our code. And so on…
If that’s the case, user code consists of a mix of infrastructure code and core code. The following figure shows what this looks like:

When I look at this diagram, I immediately feel the urge to push the bits of infrastructure code to the sides. Where they belong, I’d say, because infrastructure code is the code that connects core code to the outside world so it might as well live as close the outside world as possible.
What remains in the middle, after “defragmenting” the user code is only core code:

This is code that can be executed without relying on any actual infrastructure, and without making any connection to the world surrounding the application. No network, no database, no file system, etc. As we’ve seen in the previous chapters, this is great for testing (see also Chapter 14, A testing strategy for decoupled applications).
Completely isolated core code allows you to test the use cases of your application in a very early stage of development. You can prove that the application correctly implements its use case scenarios, without setting up routing for your web application, and without running schema migrations on any database. This is great because it allows you to work on your use cases from the start of the project, and collect design feedback, improve user stories, etc. You won’t have to spend an entire Sprint Zero on choosing and setting up all the infrastructure. You won’t have to find out that you’ve built the wrong thing when most of the development budget has already been spent. You won’t regret that you chose MongoDB instead of MySQL because you don’t have to decide on day 1 of the project.
A summary of the strategy
What does it mean to push infrastructure code to the sides? In the previous chapters we’ve already seen many refactoring steps that helped us do it. All those “tactical” refactoring techniques can be summarized by a simple strategy. Separating core code from infrastructure code can be achieved by applying the following principles:
-
Use dependency injection everywhere, let services depend on abstractions only
-
Make use cases independent of the delivery mechanism of their input
The result will be that none of the core code depends on infrastructure code on either side. At the same time, any infrastructure code would be able to call core code. There are no special requirements for doing so. Both ingredients combined result in code that is completely portable. It provides a clear view on the application’s use cases, without any distortions caused by infrastructural concerns. It can be easily tested, in complete isolation, without any special setup.
[…]
Pure object-oriented code
In the previous chapters I’ve used the word “pure” several times as a qualifier for certain types of objects. I think it’ll be useful to describe in more detail what I mean by pure objects. Knowing when code is pure or not will make a difference, because pure code can be unit-tested, and most of it can end up in the core of your application.
“Pure” as a qualifier for code originates from functional programming. A
pure function is a function with a return value that completely depends
on the arguments provided to it.
The following listing shows an example of such a pure
function. There’s nothing that could influence the outcome of calling
sum() other than the provided arguments, and the code of the function
itself:
function sum(int $a, int $b): int
{
return $a + $b;
}
The following listing on the other hand shows a function whose outcome is dependent on something other than the arguments and the code:
function secondsPassed(int $previousTimestamp): int
{
return time() - $previousTimestamp;
}
Such a function would be called ``impure’’ because its return value depends on the actual current time. There are many reasons for a function to be impure. For instance, if it tries to load a file, make a network connection, generates random data, etc. We’ve seen these situations in previous chapters and called the code that performs this kind of work infrastructure code.
Now, there are ways to make impure code pure again, or rather, split impure code into a pure part and an impure part.
The following listing shows how to do it in the case of secondsPassed(): you only need to ``push’’ out the part that made the function impure.
function secondsPassed(
int$currentTimestamp, int $previousTimestamp
): int {
return $currentTimestamp - $previousTimestamp;
}
With objects, a similar approach can be used to make impure methods pure again.
Take a look at the following listing, which shows the rather silly Stopwatch class with an impure method, which is basically the same as the impure secondsPassed() function we just saw:
final class Stopwatch
{
public function secondsPassed(int $previousTimestamp): int
{
return time() - $previousTimestamp;
}
}
If we want to make the method pure again, we have to get rid of the call to time().
In the functional example we modified the function to accept the current time as an argument instead of fetching it.
This is certainly an option here as well:
final class Stopwatch
{
public function secondsPassed(
int $currentTimestamp,
int $previousTimestamp
): int {
return $currentTime - $previousTimestamp;
}
}
There is another option, which is unique to objects.
We could inject a dependency that the secondsPassed() method can use to retrieve the current time.
The following listing shows how you could inject some kind of Timer object.
The Timer has a time() method that can be used to replace calls to time().
final class Timer
{
public function currentTimestamp(): int
{
return time();
}
}
final class Stopwatch
{
private Timer $timer;
public function __construct(Timer $timer)
{
$this->timer = $timer;
}
public function secondsPassed(int $previousTimestamp): int
{
return $this->timer->currentTimestamp()
- $previousTimestamp;
}
}
This leaves the secondsPassed() method unchanged: clients won’t have to provide the current timestamp themselves.
It does allow us to get rid of calls to time(), and replace them by calls to Timer::currentTimestamp().
But that doesn’t make Stopwatch pure yet.
Although the call to time() now only happens inside Timer, calling Stopwatch::secondsPassed() will inevitably call Timer::currentTimestamp(), which is impure.
This indirectly makes \linebreakStopwatch::secondsPassed() impure as well.
We can fix this by applying a technique we’ve already seen several times now: dependency inversion.
We should introduce a proper abstraction for ``retrieving the current time’’.
We already have a separate object for it (Timer), now we only need an interface for it.
Let’s turn Timer into an interface, and define a standard implementation for it that uses the system clock to get the current timestamp:
interface Timer
{
public function currentTimestamp(): int;
}
final class TimerUsesSystemClock implements Timer
{
public function currentTimestamp(): int
{
return time();
}
}
final class Stopwatch
{
private Timer $timer;
public function __construct(Timer $timer)
{
$this->timer = $timer;
}
public function secondsPassed(int $previousTimestamp): int
{
return $this->timer->currentTimestamp()
- $previousTimestamp;
}
}
By introducing the Timer interface, we have successfully built in the possibility to call secondsPassed() without indirectly calling time().
We can easily instantiate a Stopwatch object, with a stand-in Timer object, which simply returns a hard-coded timestamp:
final class FakeTimer implements Timer
{
private int $timestamp;
public function __construct(int $timestamp)
{
$this->timestamp = $timestamp;
}
public function currentTimestamp(): int
{
return $this->timestamp;
}
}
$stopwatch = new Stopwatch(new FakeTimer(1562845845));
Having seen the mechanism of making impure object methods pure, we could also rephrase “pure” as: deterministic. Because they only rely on method arguments and constructor-injected abstract dependencies the client has full control over the object. This results in deterministic objects, which is great for testability. There’s no special setup required. The only thing a test has to do is instantiate the object itself, providing any required dependency, and calling a method on it, providing any required argument.
Looking at the code of StopWatch we can conclude that it’s now pure:
it’s decoupled from any infrastructure class. But when the application
is running in production Stopwatch will of course call
currentTimestamp() on TimerUsesSystemClock instead of the
FakeTimer. A dependency injection container will usually take care of
the actual setup of your service object, including any of its
dependencies.
The following figure shows the
differences between both perspectives:
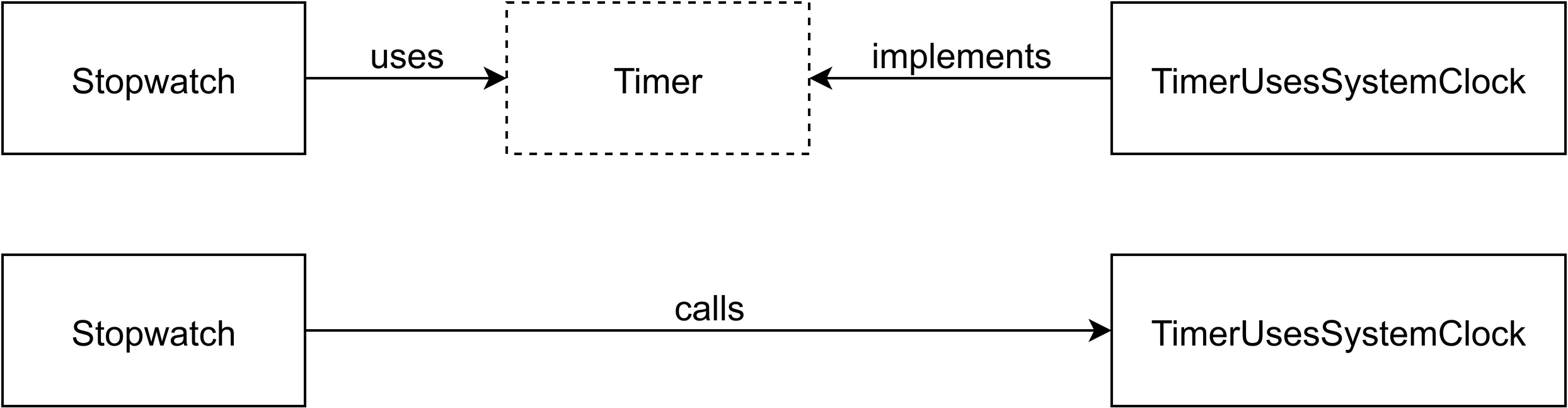
I find that when you start at a low level, the level of classes and methods, and you aim to write as much object-pure code as possible, while pushing all the infrastructure-related things to the sides, you will end up with a much better design at a higher level too. Which is why I’ve started this book focusing only on core versus infrastructure instead of architectural concepts like layering, and ports and adapters. Of course we’ll discuss these concepts in Part II - Organizing Principles, but the big win is separating core from infrastructure code. All the rest is nice-to-have, and you will get the rest more or less for free.
Summary
In this chapter we rephrased the definition of core code as code that represents the use cases of an application. Infrastructure code is code that connects these use cases to its external actors. Actors can be primary actors (users of the application) or secondary/supporting actors (other systems that our application uses). To decouple from primary actors we have to make our use cases universally invokable, regardless of the delivery mechanism that a specific type of actor supports. To decouple from secondary actors we have to apply dependency inversion and abstract any dependency that communicates directly with a secondary actor. A domain-first approach combined with a test-first approach will improve the quality of the application’s core code, making it more likely to survive the infrastructural changes in the world around it. Core code has to be object-oriented code that is “object-pure” which is quite similar to the notion of functionally pure. All dependencies are made explicit and for every dependency that connects to something outside the application an abstraction has been introduced. Object-pure code is easy to test because, by definition, it behaves in a completely deterministic way.
Interested to learn more? Buy a copy of the full book now, using the DECOUPLE_TODAY discount code.