Free book chapter: Key design patterns
Matthias Noback
I wanted to share with you a free chapter from my latest book, “Advanced Web Application Architecture”. I’ve picked Chapter 11, which gives a compact overview of all the design patterns that are useful for structuring your web application in a way that will (almost) automatically make it independent of surrounding infrastructure, including the web framework you use.
Chapter 11 is the first chapter of Part II of the book. In Part I we’ve been discovering these design patterns by refactoring different areas of a simple web application. Part II provides some higher-level concepts that can help you structure your application. Besides design patterns, it covers architectural layering, and hexagonal architecture (ports & adapters). It also includes a chapter on testing decoupled applications.
If you’re interested in this kind of topic, make sure to get a discounted copy using this link: https://leanpub.com/web-application-architecture/c/RELEASE_DAY.
Chapter 11: Key design patterns
This chapter covers:
- A catalog of design patterns
- Implementation suggestions
- A high-level design process based on these design patterns
11.1 Framework-inspired structural elements
Every framework comes with its own set of recognized element types. For instance, Symfony developers learn to create controllers, entities, form types, Twig templates, Yaml configuration files, and so on. Laravel developers also create controllers, but they need among other things: models, Blade templates, and PHP configuration files. When you take a look at the directory structure of most web application projects, you’ll immediately notice the framework that’s been used. Frameworks dictate your project structure. And frameworks also invade your code. This all sounds like frameworks are an enemy, instead of the helpful friend they presume to be, but this is a false contradiction. In infrastructure code, frameworks are your friend. In core code, they are not.
If frameworks determine the structure of your core code, you’ll end up with:
- Implicit use cases inside controllers,
- A domain model that’s coupled to its underlying infrastructure, and in general
- Code that’s coupled to the framework.
In Part I: Decoupling from infrastructure we’ve already seen many techniques to overcome these problems. We were able to extract a use case from a controller by modeling it as a framework-independent service. We extracted an entity from database interaction code. And we decoupled code from the framework by using dependency injection everywhere, and by passing contextual information as method arguments.
In this chapter we take a closer look at the types of objects that were the result of decoupling from infrastructure. Knowing more about the typical aspects of these objects will help you use them as building blocks instead of merely the result of refactoring activities. By using these objects as “primitives” you can implement all of the application’s use cases, without even choosing a framework. The framework will just be the finishing touch, the bridge between your application’s core and the outside world.
11.2 Entities
The first pattern to cover is the Entity pattern. In this book the concept of an entity is the same as the concept of an aggregate in Domain-Driven Design literature. An aggregate is an entity, including any of its child entities, and any of the value objects used inside of it. In my experience the term “aggregate” leads to a lot of confusion so I decided to use the word “entity” in this book. We have talked about entity design in Chapter 2: The domain model, and I’ve already mentioned several design rules for it there. Still, I want this chapter to be a reference guide to the standard design patterns you’ll need in decoupled application development, so I’ll briefly summarize the rules here. I’ll just declare the rules without defending them in detail. You can always look up the reasoning in Eric Evans’ “Domain-Driven Design - Tackling complexity in the heart of software”, Addison-Wesley Professional (2003). A quick and accurate primer on the topic is Vaughn Vernon’s article series “Effective Aggregate Design”.
Entities are objects that preserve the state of your application. They are the only type of objects in your application that have persistent state. Most of the other objects should be designed to be immutable and stateless. Being mutable, entities should not be passed to clients that don’t intend to change their state. When a client needs to retrieve information from an entity, in most cases they should rely on a different type of object, that is, a Read model (see Section 11.6: Read models). The only type of client that is supposed to modify an entity is an Application service (see Section 11.4).
You shouldn’t be able to traverse from one entity to the other, e.g.
$this->getLine(1)->getProduct()->getProductGroup()->getProducts()
Changes should always be limited to a single entity. If you need to modify another entity, fetch it from its own repository. Don’t make changes to multiple entities in the same transaction. Make a clear distinction between the primary change and secondary effects. Handle these effects using Event subscribers (see Section 11.5).
11.2.1 Protect invariants
An entity should always protect its domain invariants (the things that are always true about it) and make sure that it’s in a consistent state. It should never contain invalid, incomplete, or meaningless data. Entities are meant to establish a basic level of consistency for your application, as well as protecting it against data corruption.
An entity’s constructor should be a named constructor and it should force clients to provide the minimum set of required data (see the following listing). The constructor needs to verify that the data provided is valid, for instance that values are within the allowed range, have the minimum length, etc. You can use a standard set of assertions, or throw your own exceptions in case something is wrong.
An entity has a unique identity from the start. Provide it when calling the constructor.
Relations between entities should be establish by their IDs, not by providing the entire object reference.
final class Order
{
// ...
private function __construct(/* ... */)
{
// ...
}
public static function create(
OrderId $orderId,
CustomerId $customerId
): Order {
return new self(/* ... */);
}
}
11.2.2 Constrain updates
Only allow clients to update fields that can actually be modified. Force clients to update fields together when it makes sense (e.g. when you change the delivery address, clients should provide the street, number, postal code, and city in one go). Always validate the incoming data and throw exceptions when something is wrong. Verify that the requested change is possible given the current state of the entity, and that the entity won’t end up in an invalid state:
final class Order
{
private bool $wasCancelled = false;
// ...
public function changeDeliveryAddress(
DeliveryAddress $deliveryAddress
): void {
if ($this->wasCancelled) {
throw new LogicException(
sprintf(
'Order %s was already cancelled',
$this->id->asString()
)
);
}
}
}
11.2.3 Model state changes as actions with state transitions
When an update to a particular field actually represents an action performed on the object, define a method for it.
The job of this method, again, is to validate the arguments provided to it.
It also has to verify that the action is allowed, given the current state of the object.
As an example, an order may be cancelled, but only if it hasn’t been delivered yet.
Instead of a setCancelled() method, an Order entity would have a cancel() method, which performs the required checks:
final class Order
{
// ...
private bool $wasCancelled;
private bool $wasDelivered;
public function cancel(): void
{
if ($this->wasDelivered) {
throw new LogicException(
sprintf(
'Order %s has already been delivered',
$this->id->asString()
)
);
}
$this->wasCancelled = true;
}
}
Methods that change the state of the entity, or perform an action on it, should both be Command methods, that is, they should have a void return type.
While changing the delivery address of an order would be a simple update, cancelling an order has an impact on what you can do with the order. As we just saw, the same is true for delivering it. Once an order is in the “cancelled” state, it can no longer be delivered. Once an order is in the “delivered” state, it can no longer be cancelled. When you design an entity, it’ll be helpful to create a state machine diagram for it, which documents the possible states of an entity and what actions (state transitions) are available for any given state (see Figure 11.1). Create unit tests for your entity to prove that it correctly implements the state machine you had in mind.
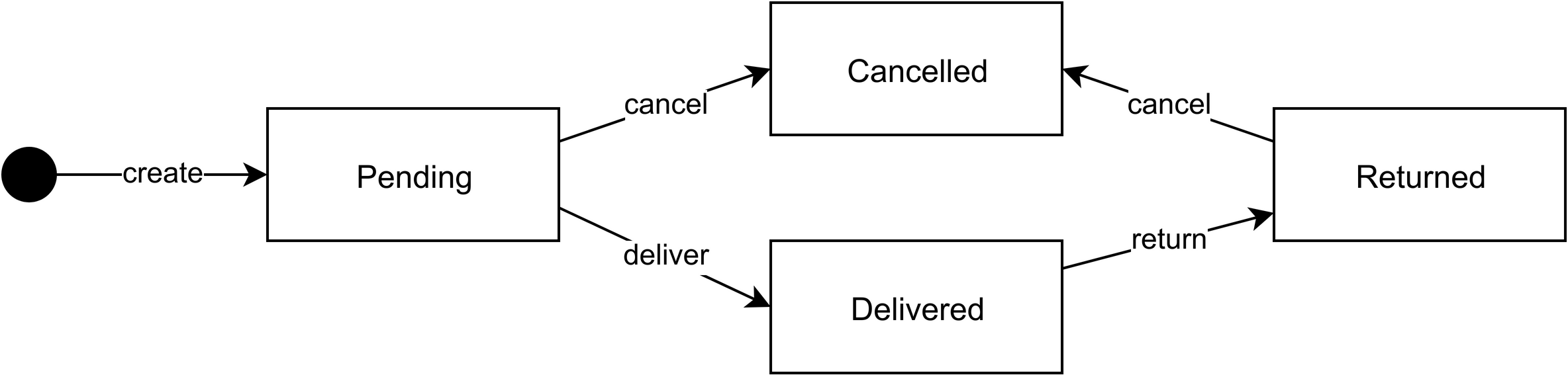
Figure 11.1 Modelling the elements that are inside the system.
11.2.4. Don’t think too much about tables
Design your object, its methods, and its properties without worrying about persistence. Mapping the data to any kind of database should be a separate task. Your entity should in the first place be a well-designed object regardless of the database that will eventually support storing it. You should always be able to define a mapping from your object to the database you want to use. In fact, you can let the design of your object determine what storage model would work best.
11.2.5 Record domain events
Keep an internal record of Domain events that have happened to the entity, like “Order was created”, “Order was cancelled”, etc.
Domain events are simple immutable objects which are named after the event they represent, e.g. OrderWasCreated, OrderWasCancelled, etc.
After saving the entity, it should be possible to retrieve a collection of these event objects so you can dispatch them and let other parts of the application respond to them.
The following listing shows a simple setup for recording events and releasing them:
final class OrderWasCancelled
{
private OrderId $orderId;
public function __construct(OrderId $orderId)
{
$this->orderId = $orderId;
}
}
final class Order
{
private array $events = [];
// ...
public function cancel(): void
{
// ...
$this->events[] = new OrderWasCancelled($this->id);
}
public function releaseEvents(): array
{
$events = $this->events;
$this->events = [];
return $events;
}
}
11.3 Repositories
Every entity needs a repository.
Because a repository crosses the application boundary to save and load entities it should be a service abstraction.
This means the repository should be defined as an interface (e.g. OrderRepository).
It also needs a standard implementation that implements the interface and the contract described by it.
There are several alternative designs for repositories, but I prefer the simplest one.
It doesn’t make a distinction between adding and updating entities:
interface OrderRepository
{
/**
* @throws CouldNotSaveOrder
*/
public function save(Order $order): void;
/**
* @throws CouldNotFindOrder
*/
public function getById(OrderId $orderId): Order;
}
The contract that this interface represents is that when you have saved an Order with a certain OrderId you can at any time retrieve a copy of it by providing that same OrderId as an argument to getById().
After making a change to Order (in fact, after changing it in any of the ways that it allows), the object can be saved again using save().
And it can also be retrieved by calling getById().
The object you get back from OrderRepository could be the exact same instance, or an object that behaves in an identical way to the one you saved.
For OrderRepository implementations that save Order instances to an actual database, implementing this contract can take some effort.
But creating a test double for this contract is actually really simple:
final class InMemoryOrderRepository
implements OrderRepository
{
/**
* @var array<string,Order>
*/
private array $orders = [];
public function save(Order $order): void
{
$this->orders[$order->orderId()->asString()] = $order;
}
public function getById(OrderId $orderId): Order
{
if (!isset($this->orders[$orderId->asString])) {
throw CouldNotFindOrder::withId($orderId);
}
return $this->orders[$orderId->asString()];
}
}
That’s too easy!
Yes, the in-memory repository implementation is really simple. Things will be more complicated when you implement the repository that will save the entity to the real database. As we discussed in Chapter 2 there are different options. You can still use an ORM and delegate some of the logic at the cost of loosing some explicitness as well as control. If you decide to write your own mapping implementation keep the following requirements in mind.
When you save an entity you need to know if it’s a new entity or an existing one that’s being updated. Based on this knowledge you should do either an
INSERTor anUPDATEquery. You can create something known as an identity map where you keep track of entities that have been loaded from the database. The next time the application tries tosave()an entity you look it up in the identity map. If it’s there, it needs to be updated, if it isn’t there it needs to be inserted. After the insert you add the entity to the identity map so saving it once more will trigger an update. An alternative (something I’ve used in TalisORM) is to let the entity itself keep track of whether or not it’s “new”.If the entity has child entities, you need to do the same kind of change tracking for these entities as well. Child entities can often be deleted too so there should be a way to find out when a
DELETEquery is needed. And before you know it you’ll be implementing your own ORM so it’s good to keep an eye on the cost/benefit ratio. In the past few years I personally have experienced some great benefits from writing my own mapping code, but make sure to fully consider your own context before taking this route.
11.4 Application services
The Order entity can be created, you can change its delivery address, cancel it, etc.
These behaviors are represented by command methods, with an intention-revealing name.
Only Application services should have access to these methods.
An application service coordinates the requested change.
For instance, it creates the Order and saves it to the OrderRepository.
Or it loads an Order entity by its ID, calls one or more methods on it, and saves it again:
final class CreateOrderService
{
private OrderRepository $orderRepository;
public function __construct(OrderRepository $orderRepository)
{
$this->orderRepository = $orderRepository;
}
public function __invoke(/* ... */): OrderId
{
$orderId = $this->orderRepository->nextIdentity();
$order = Order::create(
$orderId,
/* ... */
);
$this->orderRepository->save($order);
return $order->id();
}
}
final class ChangeDeliveryAddressService
{
private OrderRepository $orderRepository;
public function __construct(OrderRepository $orderRepository)
{
$this->orderRepository = $orderRepository;
}
public function __invoke(OrderId $orderId /* ... */): void
{
$order = $this->orderRepository->getById($orderId);
$order->changeDeliveryAddress(/* ... */);
$this->orderRepository->save($order);
}
}
An application service could have a single method (e.g. an __invoke() method).
In that case the service represents a single use case as well.
But since several uses cases may share the same set of dependencies you may also create a single class with multiple methods:
final class OrderService
{
private OrderRepository $orderRepository;
public function __construct(
OrderRepository $orderRepository
) {
$this->orderRepository = $orderRepository;
}
public function createOrder(/* ... */): OrderId
{
$orderId = $this->orderRepository->nextIdentity();
// ...
return $orderId;
}
public function changeDeliveryAddress(/* ... */): void
{
// ...
}
public function markAsDelivered(/* ... */): void
{
// ...
}
public function cancel(/* ... */): void
{
// ...
}
}
11.4.1 Return the identifier of a new entity
Application service methods are command methods: they change entity state and shouldn’t return anything.
However, when an application service creates a new entity (like the createOrder() method we just saw), you may still return the ID of the new entity.
One thing an application service definitely should not return is the complete entity.
As explained before, an entity is a write model with built-in behaviors for changing its state.
It should not be available to clients that don’t want to change its state.
Clients of application services are usually controllers and they certainly shouldn’t change entity state.
What if you want to return some information about the entity in the response?
In that case use the ID that was returned by the application service to fetch a view model from its view model repository:
final class OrderController
{
// ...
public function createOrderAction(Request $request): Response
{
$orderId = $this->orderService->createOrder(/* ... */);
$order = $this->orderDetailsRepository->getById($orderId);
return $this->templateRenderer->render(
'order-details.html.twig',
[
'order' => $order
]
);
}
}
See Section 3.5 for more information about view models.
11.4.2 Input should be defined as primitive-type data
The client of an application service is usually some kind of a controller, like a web controller or a console command. Another client could be a test that invokes the service. We’ll see an example of this in Chapter ??: Testing strategy.
To make an application service fully portable, allowing any type of client to use the service, you should make the input arguments easy to create. The best way to do that is to use primitive-type parameters only:
final class OrderService
{
// ...
public function changeDeliveryAddress(
string $orderId,
string $address,
string $postalCode,
string $city,
string $country
): void {
// ...
}
}
11.4.3 Wrap input inside command objects
You can introduce Parameter object which combines all the parameters in a single object:
final class ChangeDeliveryAddress
{
private string $orderId;
private string $address;
private string $postalCode;
private string $city;
private string $country;
public function __construct(
string $orderId,
string $address,
string $postalCode,
string $city,
string $country
) {
$this->orderId = $orderId;
$this->address = $address;
$this->postalCode = $postalCode;
$this->city = $city;
$this->country = $country;
}
public function orderId(): string
{
return $this->orderId;
}
public function address(): string
{
return $this->address;
}
// ...
}
final class OrderService
{
public function changeDeliveryAddress(
ChangeDeliveryAddress $command
): void {
// ...
}
}
A parameter object for an application service is a data-transfer object (DTO).
In the controller you should copy the data from the request into the DTO, which then carries it to the application service.
Use the class name of the DTO to communicate intent.
If the data is going to be used to change the delivery address of an order, the name should be ChangeDeliveryAddress.
This makes it a Command object (not to be confused with the Command design pattern) and the application service becomes a Command handler.
When copying data from the request into the command object, don’t throw exceptions when you encounter bad input (as discussed in Chapter 8: Validation).
The only thing you have to do is ensure that the request data is cast to the correct types, that all the fields have a value assigned to them or are null if that’s an allowed value:
final class CreateOrder
{
use Mapping;
// ...
public static function fromRequestData(array $data): self
{
return new self(
self::getString($data, 'email'),
self::getInt($data, 'ebook_id'),
self::getInt($data, 'quantity'),
self::getNonEmptyStringOrNull($data, 'buyer_name')
);
}
}
11.4.4 Translate primitive input to domain objects
An application service has to translate the primitive-type values from the DTO to the value objects that the entity can work with.
The following listing shows how the application service takes the input and creates a value object which can be passed to the Order::changeDeliveryAddress() method:
final class OrderService
{
private OrderRepository $orderRepository;
// ...
public function changeDeliveryAddress(
ChangeDeliveryAddress $command
): void {
$order = $this->orderRepository->getById(
OrderId::fromString($command->orderId())
);
// ...
$order->changeDeliveryAddress(
DeliveryAddress::fromScalars(
$command->address(),
$command->postalCode(),
$command->city(),
$command->country()
)
);
// ...
}
}
This helps keep the knowledge about how to deal with domain objects inside the core of the application, and not in infrastructure code like the controller. It also ensures that entities and value objects will only throw exceptions once the application service has been invoked. This way, the controller still has a chance to validate the command object itself and show form errors to the user.
However, application services tend to become long lists of these primitive-value-to-value-object transformations, which obscures the view on the the actual use case that the service represents. As an alternative you can add accessor methods to the command object which instantiate and return the correct value objects themselves:
final class ChangeDeliveryAddress
{
private string $orderId;
private string $address;
private string $postalCode;
private string $city;
private string $country;
public function orderId(): OrderId
{
return OrderId::fromString($this->orderId);
}
public function deliveryAddress(): DeliveryAddress
{
return DeliveryAddress::fromScalars(
$this->address,
$this->postalCode,
$this->city,
$this->country
);
}
}
final class OrderService
{
private OrderRepository $orderRepository;
// ...
public function changeDeliveryAddress(
ChangeDeliveryAddress $command
): void {
$order = $this->orderRepository->getById($command->orderId());
// ...
$order->changeDeliveryAddress(
$command->deliveryAddress()
);
// ...
}
}
This approach has several advantages:
- There’s less noise inside the application service because it doesn’t have to deal with all the type conversions itself.
- The getters on the command DTO can be called multiple times inside the application service. There’s no need to duplicate the instantiation logic.
A possible downside is that you could accidentally trigger a domain-level exception inside the controller by calling one of those getters. In practice I find that this doesn’t get in the way and is just something to be aware of.
11.4.5 Add contextual information as extra arguments
Contextual data like the current user’s ID, data from the current HTTP request, etc. should not be fetched when needed, nor should it be injected as constructor arguments of the application service.
Instead, contextual information should always be provided as method arguments.
If you want to store the current user’s ID on the Order entity, make sure to pass it as an argument to the CreateOrderService:
final class OrderService
{
// ...
public function changeDeliveryAddress(
ChangeDeliveryAddress $command
): void {
// The current user ID is part of the command data:
$userId = $command->userId();
// ...
}
}
// In the controller:
$this->orderService->changeDeliveryAddress(
ChangeDeliveryAddress::fromRequestData(
$request->request->all(),
$user->userId()
)
)
11.4.6 Save only one entity per application service call
An application service should only make changes to a single entity. This can help improve the domain model’s performance, both in terms of processing changes in the database, and in preventing concurrent updates. It helps keep your use cases focused on a limited area of the domain. There is just one thing that the service has to do.
11.4.7 Move secondary tasks to a domain event subscriber
A change in one entity often requires other things to be done as well. Maybe another entity needs to be updated too. Maybe you have to send someone an email about the change, or push a message to a queue. For these secondary effects use domain events, an event dispatcher, and event subscribers. Figure 11.2 shows how these elements work together.
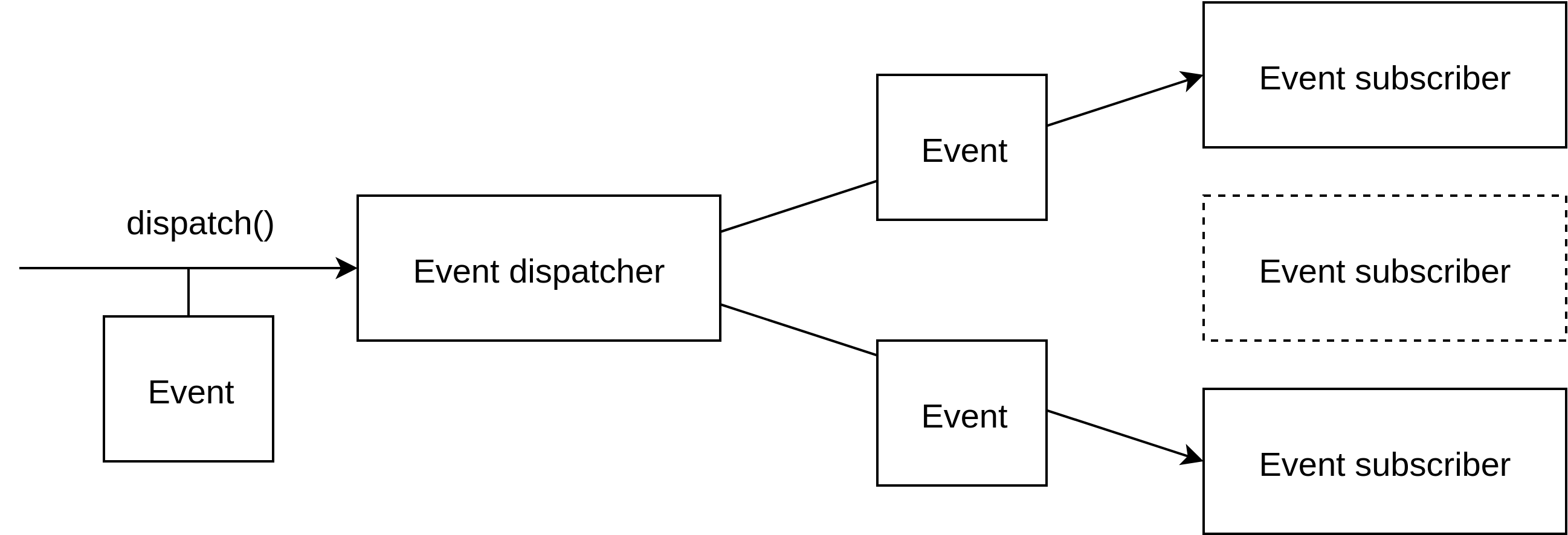
Figure 11.2 A client sends an event object to the event dispatcher. The dispatcher forwards the event to any subscriber that is known to be interested in events of that type.
Events are created inside the entity and after the entity itself has been saved they can be taken out by the application service and sent to the event dispatcher (as discussed in Section 4.5). So you shouldn’t dispatch the events until you are certain that the entity’s changes have been persisted. In order to dispatch events an application service should have the event dispatcher service as one of its dependencies. It should be injected by its interface:
final class OrderService
{
private OrderRepository $orderRepository;
private EventDispatcher $eventDispatcher;
public function __construct(
OrderRepository $orderRepository,
EventDispatcher $eventDispatcher
) {
$this->orderRepository = $orderRepository;
$this->eventDispatcher = $eventDispatcher;
}
public function changeDeliveryAddress(
OrderId $orderId,
ChangeDeliveryAddress $command
): void {
// ...
$order->changeDeliveryAddress(
DeliveryAddress::fromScalars(
$command->address,
$command->postalCode,
$command->city,
$command->country
)
);
$this->orderRepository->save($order);
$this->eventDispatcher->dispatchAll(
$order->releaseEvents()
);
}
}
An application service may make multiple changes to an entity causing multiple events to be recorded and released. An entity may also record multiple events for a single action. This could happen when a change to an entity means different things to different observers. Or when an update brings the entity into some new state:
final class Order
{
// ...
public function markLineAsDelivered(int $lineNumber): void
{
$this->line($lineNumber)->markAsDelivered();
$this->events[] = new LineDelivered($this->id, $lineNumber);
if ($this->allLinesHaveBeenDelivered()) {
$this->events[] = new OrderFullyDelivered($this->id);
}
}
}
11.5 Event subscribers
After saving an entity the event dispatcher should receive all the recorded domain events. The event dispatcher will then notify all the event subscribers that have been registered for that particular event. The following listing shows how a simple event dispatcher would do that. All subscribers in this example are provided as a constructor argument. Each subscriber is supposed to be a callable.
interface EventDispatcher
{
public function dispatchAll(array $events): void;
}
final class SimpleEventDispatcher implements EventDispatcher
{
private array $subscribers;
public function __construct(array $subscribersByEventType)
{
$this->subscribers = $subscribersByEventType;
}
public function dispatchAll(array $events): void
{
foreach ($events as $event) {
foreach (
$this->subscribersForEvent($event) as $subscriber
) {
$subscriber($event);
}
}
}
private function subscribersForEvent(object $event): array
{
return $this->subscribers[get_class($event)] ?? [];
}
}
The following listing shows how you’d register an event subscriber for the OrderFullyDelivered event:
final class CreateInvoice
{
private InvoicingService $invoicingService;
public function __construct(
InvoicingService $invoicingService
) {
$this->invoicingService = $invoicingService;
}
public function whenOrderFullyDelivered(
OrderFullyDelivered $event
): void {
$this->invoicingService->createInvoiceFromOrder(
$event->orderId(),
/* ... */
);
}
}
$eventSubscriber = new CreateInvoice(/* ... */);
$eventDispatcher = new SimpleEventDispatcher(
[
OrderFullyDelivered::class => [
[$eventSubscriber, 'whenOrderFullyDelivered']
]
]
);
Instantiating services and injecting them as dependencies is something a dependency injection container should do for you. The example just shows what the logic inside the container would look like.
11.5.1 Move event subscribers to the module where they produce their effect
The class name of an event subscriber should describe what it’s going to do, e.g. “create an invoice”. The methods of the event subscriber should describe when it’s going to do this. Doing so allows you to move event subscribers to the area where they produce their effect. For instance, invoicing might be handled in a completely different part of the application. It would damage the ability to decouple modules from each other if the order module would reach out to the invoicing module and start calling methods there. Figure 11.3 shows how doing so establishes a dependency from the order module to the invoicing module.
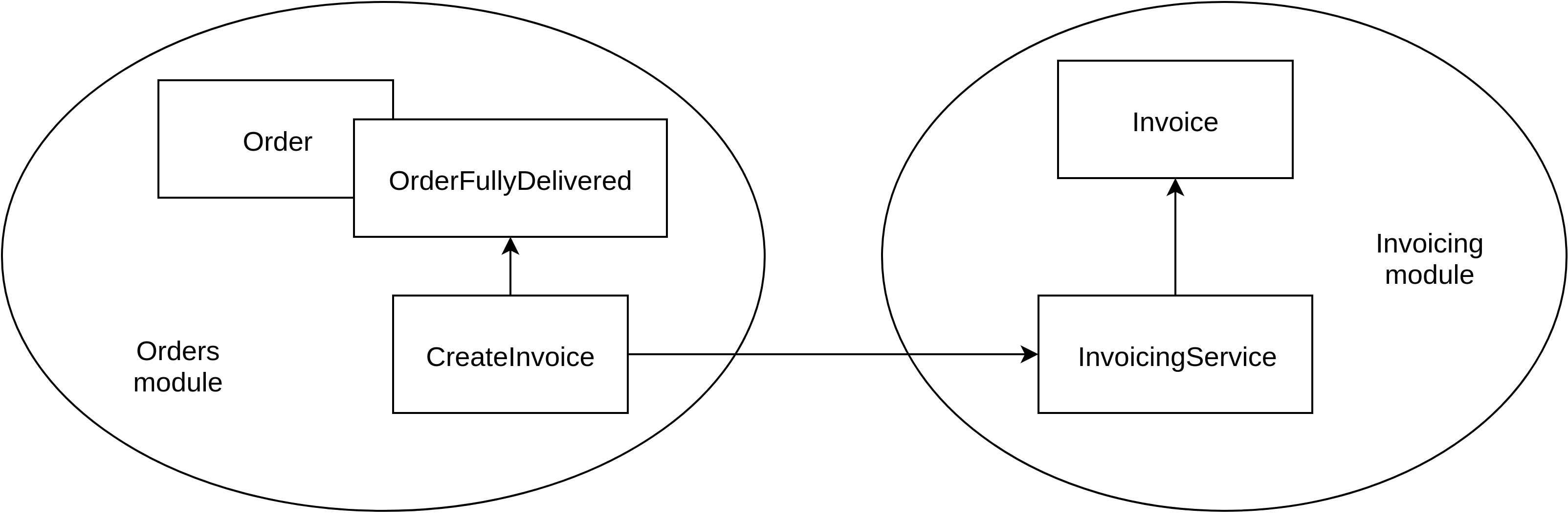
Figure 11.3. The CreateInvoice subscriber, which lives in the Orders module, uses the the InvoicingService from the Invoicing module, establishing a dependency from the Orders module to the Invoicing module.
The order comes first, and determines what needs to be invoiced.
The invoice comes second, and it’s based on data from the order.
So the order module is upstream, the invoicing module is downstream.
We should reflect that in the way we set up the event subscribers too.
The CreateInvoice subscriber should live in the invoicing module and subscribe itself to events that are produced inside the order module.
Whenever the OrderFullyDelivered event occurs it starts creating the invoice, which is an entity managed by the invoicing module.
By arranging things that way the orders module doesn’t have to know anything about the invoicing module.
The invoicing module doesn’t have to be explicitly told to create an invoice; it will respond to the fact that an order was fully delivered.
Figure 11.4 shows how moving the CreateInvoice subscriber to the invoicing module establishes the desired dependencies between these modules.
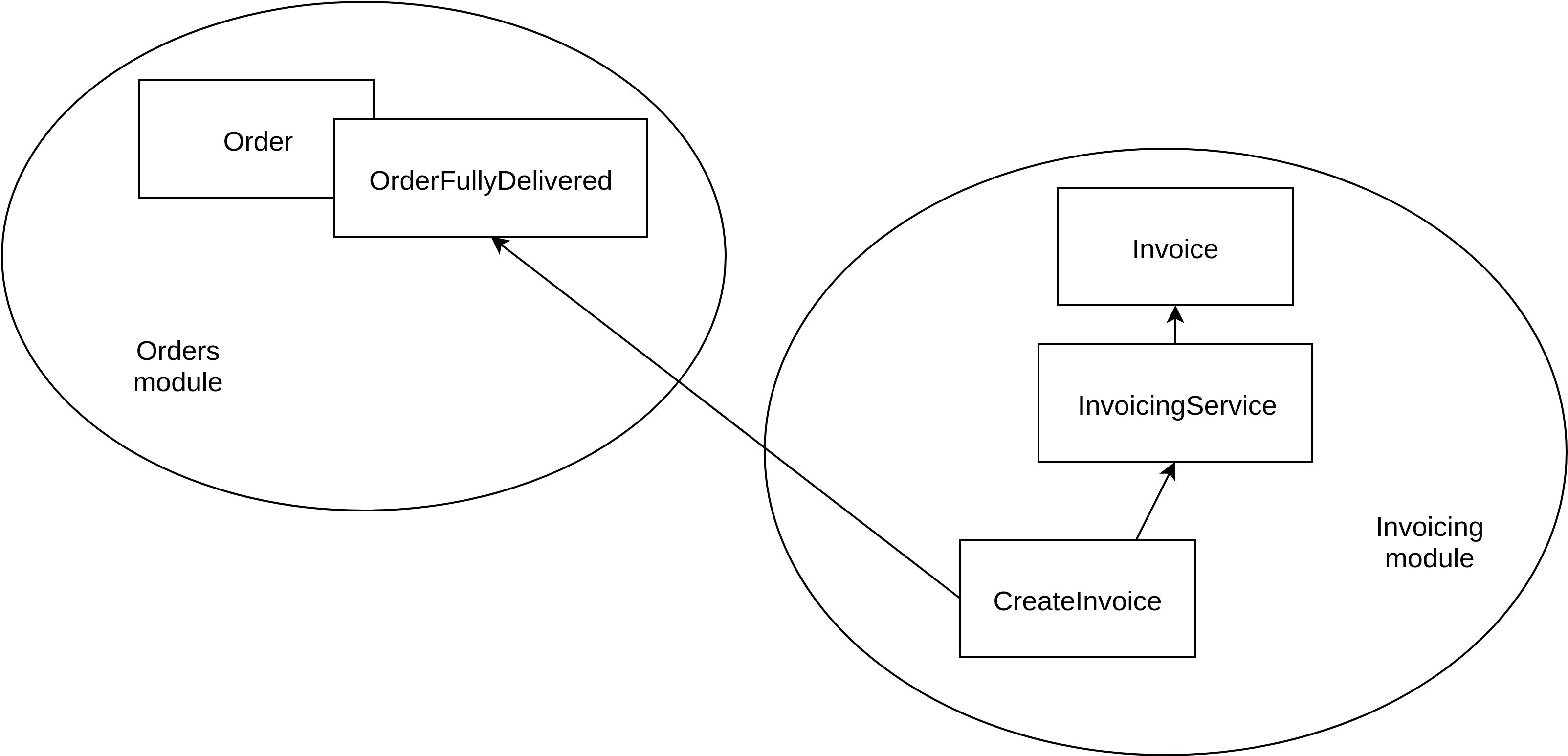
Figure 11.4. Moving the CreateInvoice subscriber to the Invoicing module, establishes the correct dependency direction: the Invoicing now depends on Orders instead of the other way around.
11.5.2 Delegate to an application service
The job of some event subscribers may be to respond to changes in one entity with an update of another entity. This would be a classic case of Eventual consistency: the system’s state will be consistent only after all event subscribers are finished. Instead of making the change inside the event subscriber, delegate the call to an application service. This application service should then follow the standard pattern of retrieving an entity, making a change to it, and saving it again.
Most event subscribers should be independent from infrastructure and only contain core code because they are a crucial part of the use case. But there may be infrastructure-specific event subscribers in your application too. For instance, subscribers that log domain events, send them to a queue, store them in a database, or something like that. Infrastructure-specific event subscribers don’t need to delegate their job to an application service. In fact, they can’t, because an application service can’t do any infrastructure work; it’s supposed to be core code. So with infrastructure-level event subscribers you just do whatever you need to do inside the event subscriber itself. Of course, you can always delegate some of the work to other (infrastructure) services that you inject as constructor arguments of the event subscriber.
11.6 Read models
While application services deal with entities, which are write models, a client that needs information from an entity shouldn’t use the entity itself but a dedicated Read model instead. There are internal and external read models (which are often called view models, see Section 11.6.3). Let’s start with internal read models.
11.6.1 Use internal read models when you need information
Given a client and its need for information, start by defining a new type of object that would be able to provide this information.
For example, the InvoicingService is going to create an invoice for an order so it needs to know a few things about the order.
In InvoicingService act as if it already existed:
final class InvoicingService
{
// ...
public function createInvoiceForOrder(OrderId $orderId)
{
// ...
$invoice = Invoice::create(
$order->customerId(),
$order->billingAddress()
);
foreach ($order->lines() as $line) {
$invoice->addLine(
$line->productDescription(),
$line->quantity(),
$line->tariff()
);
}
// ...
}
}
Your IDE will help you generate the outline for the new object by automatically creating the classes and methods that don’t exist yet:
final class Order
{
// ...
public function customerId(): CustomerId
{
// ...
}
public function billingAddress(): string
{
// ...
}
/**
* @return array<Line>
*/
public function lines(): array
{
// ...
}
}
final class Line
{
// ...
public function productDescription(): string
{
// ...
}
public function quantity(): int
{
// ...
}
public function tariff(): Money
{
// ...
}
}
Note that the Order read model is part of the Invoicing module.
That way, Invoicing is the owner of the object’s API so it can be easily modified to meet future needs of the InvoicingService.
The InvoicingService should be able to retrieve an instance of the Order read model from a Repository, which should also be owned by the Invoicing module.
To separate the what from the how of retrieving a read model object, first create a repository interface on which InvoicingService can depend:
interface OrderRepository
{
public function getById(OrderId $orderId): Order;
}
final class InvoicingService
{
private OrderRepository $orderRepository;
public function __construct(OrderRepository $orderRepository)
{
$this->orderRepository = $orderRepository;
}
public function createInvoiceForOrder(OrderId $orderId)
{
$order = $this->orderRepository->getById($orderId);
$invoice = Invoice::create(
$order->customerId(),
$order->billingAddress()
);
// ...
}
}
Separating the interface and the implementation gives you a lot of flexibility.
In a test scenario you can replace the OrderRepository dependency of the InvoicingService with a simpler, faster version.
We can let it return any Order read model object we need.
Figure 11.5 shows the dependencies between the Order and Invoicing modules.
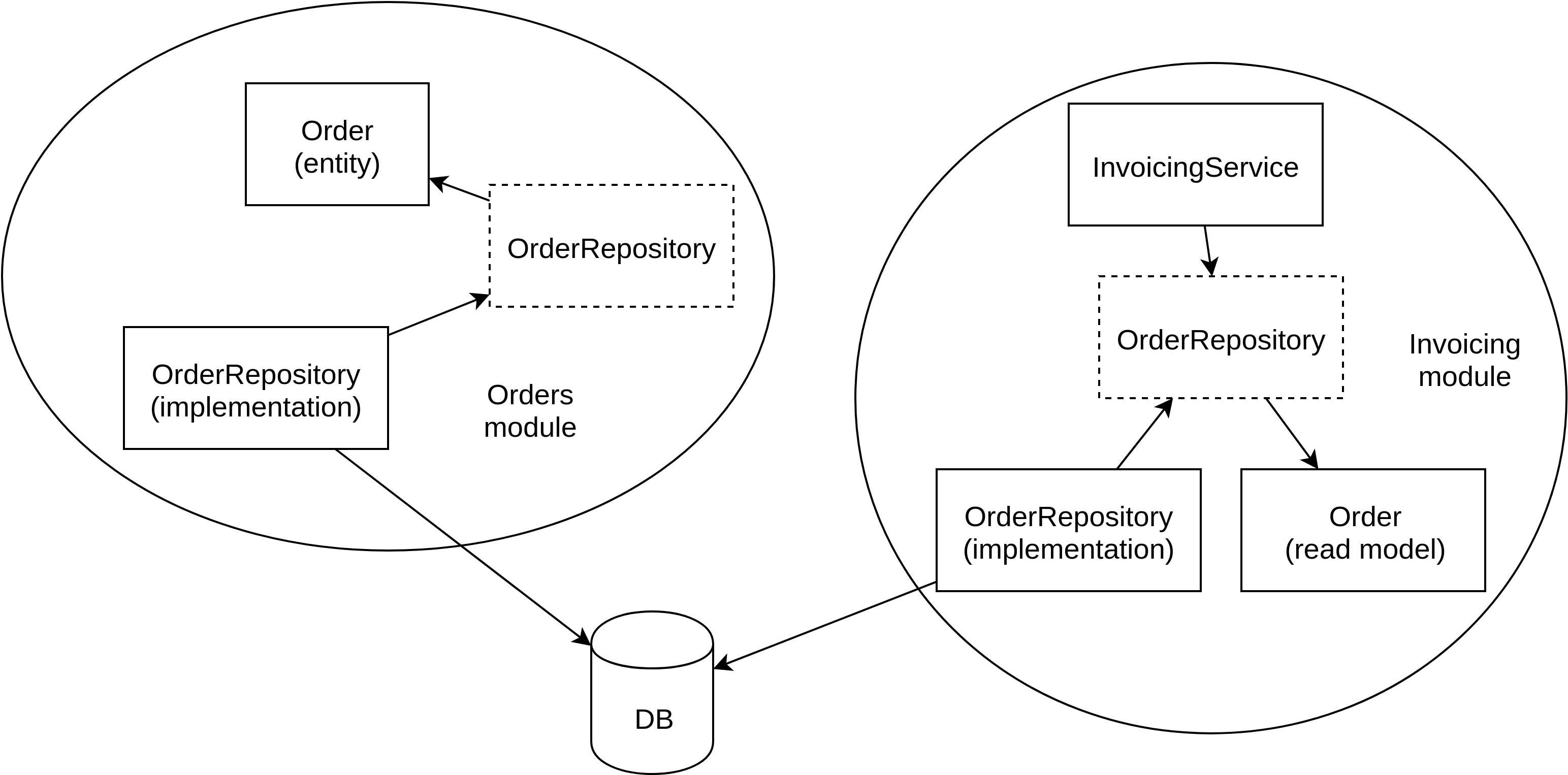
Figure 11.5. In this example, there is no code-level dependency between Invoicing and Orders. However, both modules use the same database to get their data.
11.6.2 Choose a standard implementation for the repository
The read model repository implementation will fetch the required data and create the desired Order read model objects.
It can do this in several ways, for example:
- The repository can use the same database as the one used by the write model. In that case the repository will copy data from the relevant tables and populate the read model object with it.
- The application can build up a read model based on domain events from the write model. The repository would then return the current state of the read model.
We’ve already discussed these options in detail in Chapter 3: Read models and view models.
Whatever changes are made outside of the module, as long as the repository implementation is able to provide the right read model objects, everything should be fine.
It’s like the Dependency Inversion Principle applied to models.
Even if the Orders module gets replaced by a third-party platform for selling e-books, the Invoicing module doesn’t need to suffer.
The only thing that needs to be done is rewrite the OrderRepository implementation to use the third-party platform’s API to retrieve information about an order (see Figure 11.6).
This makes the use of read models as local representations of remote entities a very powerful architectural technique.
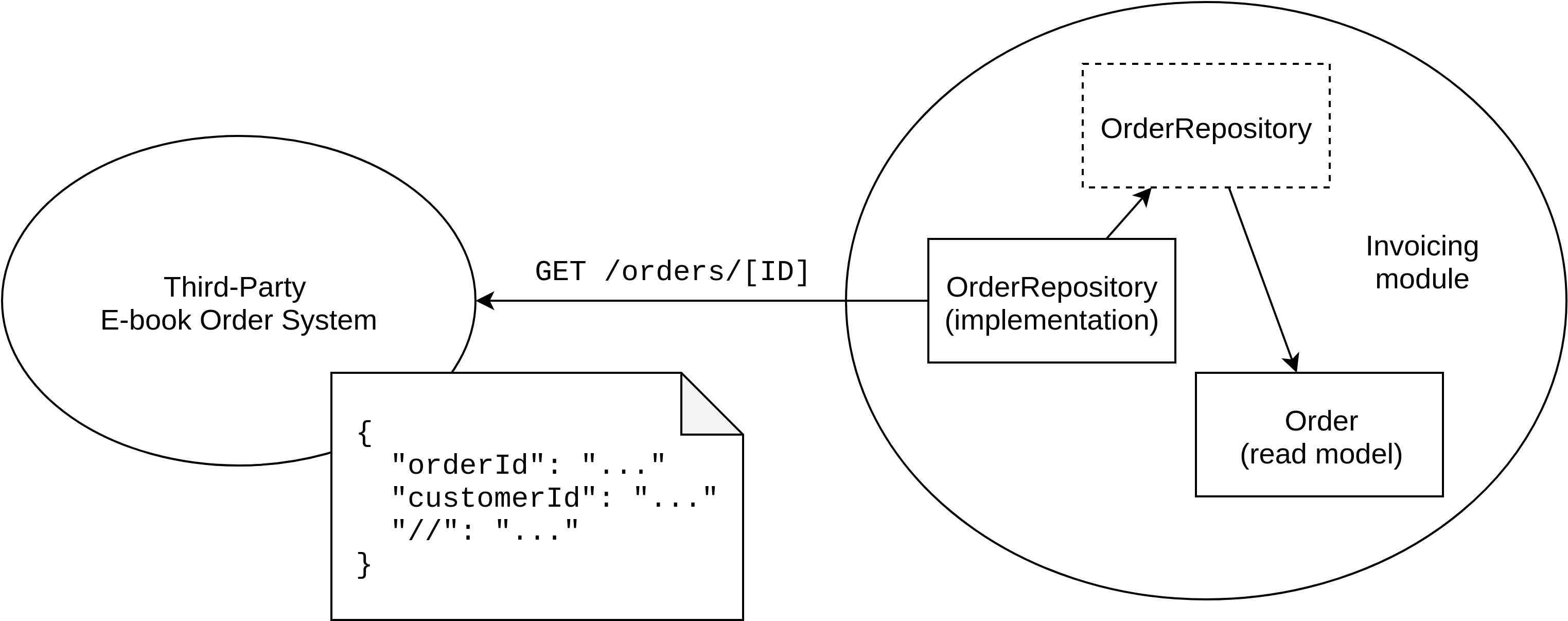
Figure 11.6. In this example, Orders has been completely replaced by a third-party system. Invoicing’s OrderRepository implementation now uses that system’s API to fetch order information.
11.6.3 For view models, prepare the data for rendering
Besides internal read models there are also outward-facing models which expose data to primary actors.
In our example, Invoicing may have an HTTP API too, allowing clients to fetch a JSON representation of an invoice.
In that case, Invoicing manages the invoice data because it owns the Invoice entity but it also provides a view on that data.
In fact, it provides multiple views because it also provides a list of unpaid invoices on the website, and allows users to download an invoice as a PDF file.
Figure 11.7 shows these different view models that Invoicing offers to its actors.
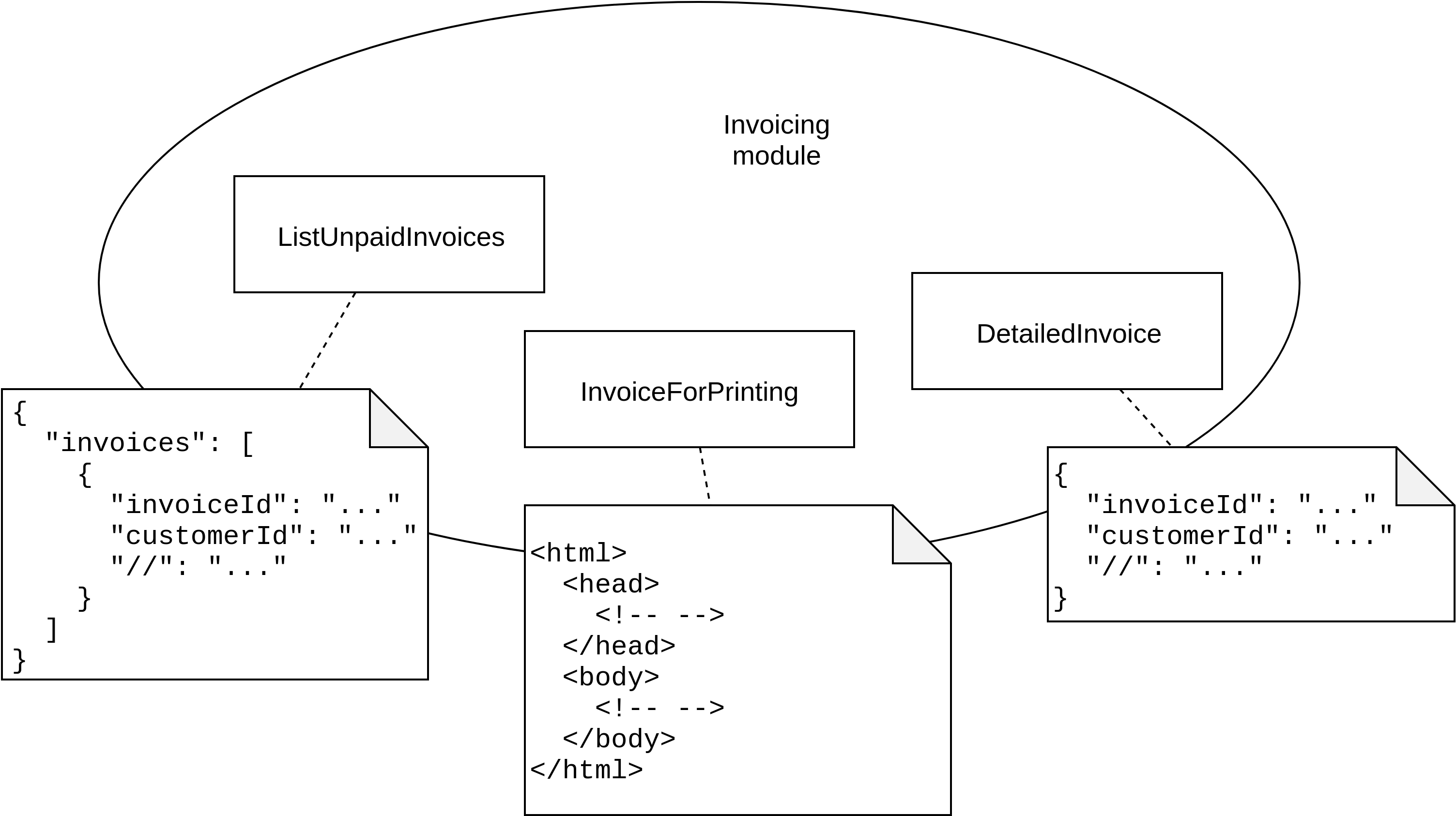
Figure 11.7. Invoicing offers several ways for clients to learn more about the data it manages.
The view models themselves need to be fully prepared for the view that renders them to the user.
For instance, if the view model is going to be used to render an HTML template, make sure that the template renderer doesn’t need to do much more than just echo a couple of properties, loop over some property, echo some more properties, etc.
If the view model is going to be rendered as a JSON object, make sure that the object can be encoded to JSON in a single step.
11.7 Process modelling
We started this chapter with a discussion about framework-inspired architecture. Frameworks propose a number of elements that should be used to build your application: controllers, models, templates, etc. In the previous sections we discussed an alternative set of elements that can also be used to build your application: entities, repositories, application services, events, event subscribers, read models, and view models. The difference of course is that when using elements like application services and entities as building blocks, your design doesn’t depend on a framework nor on any other piece of infrastructure.
This new set of elements clearly describes the use cases of your application: what you can do with it, what the consequences are, and which information the application exposes, without talking about implementation details. Being able to leave out implementation details is a sign that we can use these elements in high-level modelling sessions. You’ll find this modelling technique explained by Alberto Brandolini in “Introducing Event Storming”. There he calls it “Process Modelling”. In my experience it’s a very useful technique. It fits well between higher-level design sessions where the focus is on the problem domain, and lower-level design sessions where the programmers want to take a step in the direction of the solution. In a process modelling session they can use domain concepts and knowledge about the desired process and create a useful model for the software based on design patterns that are familiar to them. Figure 11.8 can be used as a reference for such a session.
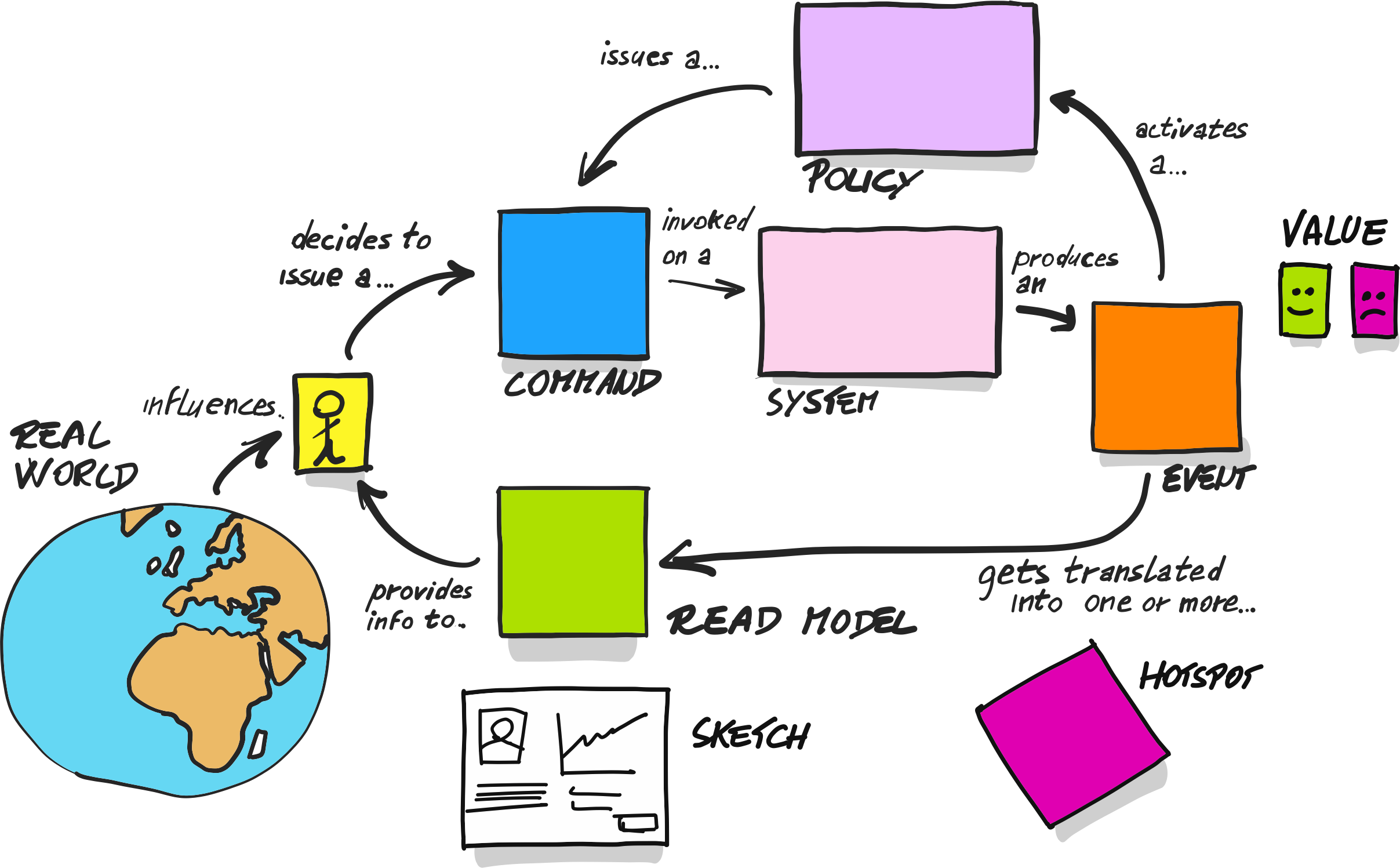
Figure 11.8. The picture that explains everything (copied with permission).
After years of developing software, for me it was a pretty revolutionary idea to consider the user as someone who is influenced by the real world, who lets the system inform them about something, and who then makes a decision based on this information. I realized that retrieving information from a system should be considered an important use case, just as important as a use case where the user decides to do something. I also realized that to successfully decouple from infrastructure both types of use cases should exist somewhere in the core code of the application.
As shown in Figure 11.8, during a process modelling session you will design commands, events, read models, effects, and decisions (policies). I personally like to take it one step further by zooming in on that “System” box. What happens inside the system should be an implementation detail and it doesn’t matter for the overall process. But since we have established some useful patterns, like application services and event subscribers, we can add those elements to the diagram as well. Figure 11.9 shows what’s inside the system. If you like, you can use an adapted process modelling session to describe these elements too.
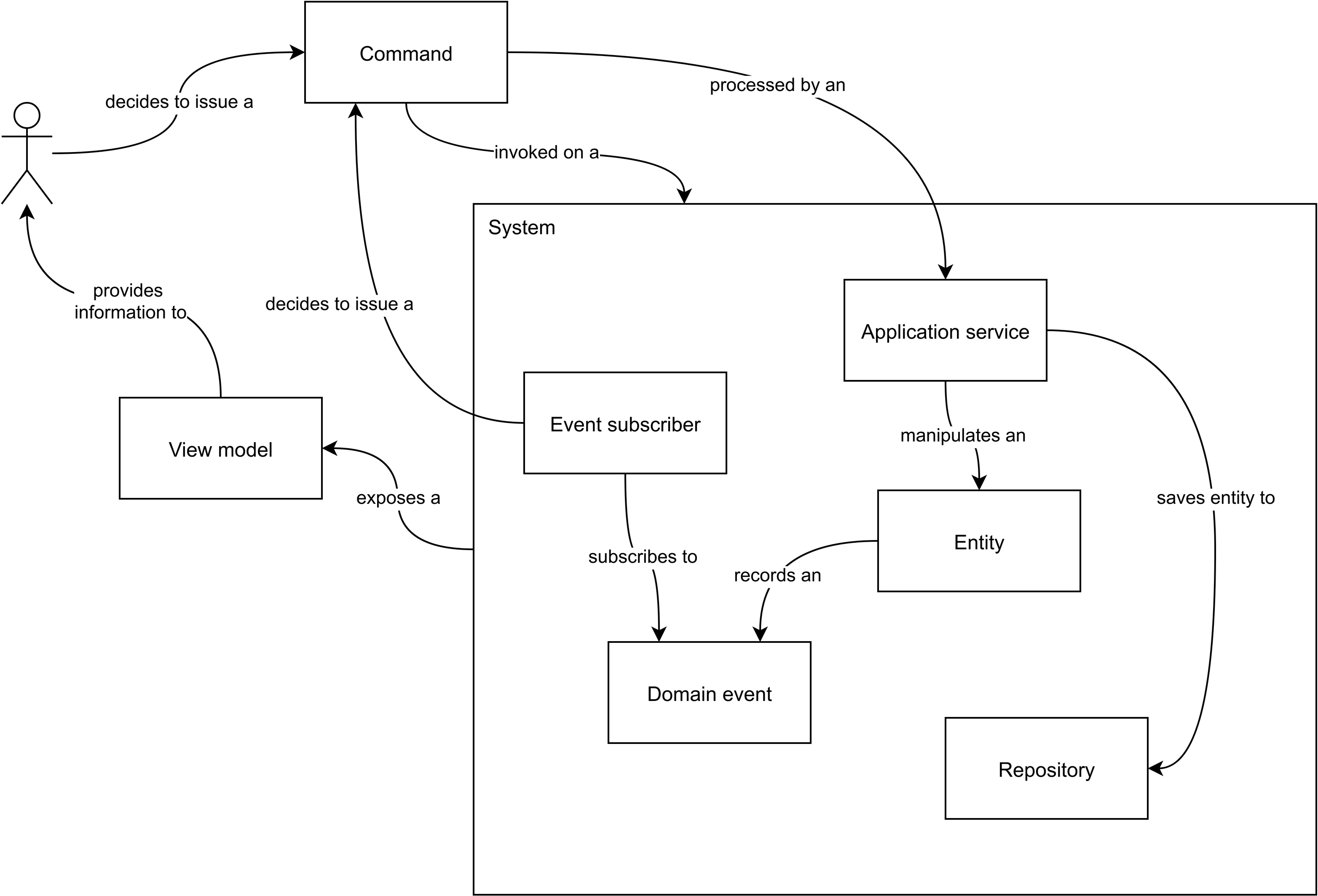
Once you know the elements of the process, how they are named, and how they interact, you also have a rough idea about how to implement those elements because you know their underlying design patterns. So you can start working on the implementation with less fear and fewer doubts. Implementing use cases becomes more like following a recipe. Understanding use cases implemented by others also becomes easier, because you recognize the same patterns in their work.
Finally, because these design patterns are decoupled from infrastructure by design, they will come in very handy when you start specifying and testing your use cases using scenarios. We’ll see how this works in Chapter ??: Testing strategy.
11.8 Summary
In this chapter we took a closer look at some of the design patterns we discovered in Part I: Decoupling from infrastructure: entities, repositories, application services, read and view models, domain events, and event subscribers. Using these patterns in your application will automatically make it easier to keep core and infrastructure code separated. They allow you to clearly define all the use cases of your application, without mixing in any infrastructural concerns. These use cases are represented in code by:
- Application services, which create or manipulate an entity, save it to the entity’s repository, and dispatch domain events produced by the entity.
- View models, which provide a useful representation of the application’s data.
Event subscribers act as a bridge between a primary change, and any number of intended effects of that change.
You can use these design patterns in a process modelling session to find out which elements you need to build.
Interested to find out more?
Get your copy of the book now, with a 10% discount: https://leanpub.com/web-application-architecture/c/RELEASE_DAY.