
Something that always bothers me: persistence (the user interface too, but that's a different topic ;)). Having objects in memory is nice, but when the application shuts down (and for PHP this is after every request-response cycle), you have to persist them somehow. By the way, I think we've all forever been annoyed by persistence, since there's an awful lot of software solutions related to object persistence: different types of databases, different types of ORMs, etc.
Why is persistence annoying?
Let's say you start out with an entity which...
- you've carefully developed using TDD,
- hides its internal data structures,
- protects its domain invariants by only allowing only valid state transitions, and
- has a public API that is well-aligned with the language of the business domain.
This is all very nice and by-the-book. But no matter how much attention you pay to the design of your objects, when they are going to be persisted, you have to break encapsulation and allow some large and unfriendly object-relational mapper to reach into the object and grab all the data it's carrying so carefully. Not only can the mapper take data from any attribute, it can also modify the value of any attribute. Your object now has one extra use-case ("persisting the object") which breaks your object's encapsulation powers, violating all the rules you previously established for the regular clients of the object.
Still, like I said, we have to persist the object, so even though this is sad, we have to live with it, and make the best of it.
Based on recent experiences I've established a very clean and effective workflow for dealing with persistence for these well-designed domain objects. I wanted to share this approach here, because I thought it might be helpful for some of you, and because I'd like to get some feedback on it.
Step 1: Follow aggregate design rules
In the first place, read Vaughn Vernon's Aggregate Design Rules and do your very best to follow these rules. You will end up with:
- Small aggregates, to allow for short and small transactions.
- No huge graphs of related objects; objects are linked only by their IDs, not by object references.
Step 2: Implement a method for extracting state
The second step was the result of some thinking and fiddling. Usually, a mapper will use reflection to reach into an object, then getting data out or putting it back in. Since this is creates such a wide "gap" in the boundaries of the object, I wanted to try something else. Why wouldn't the object hand over its own state, using a dedicated method, like getState() or getData()?
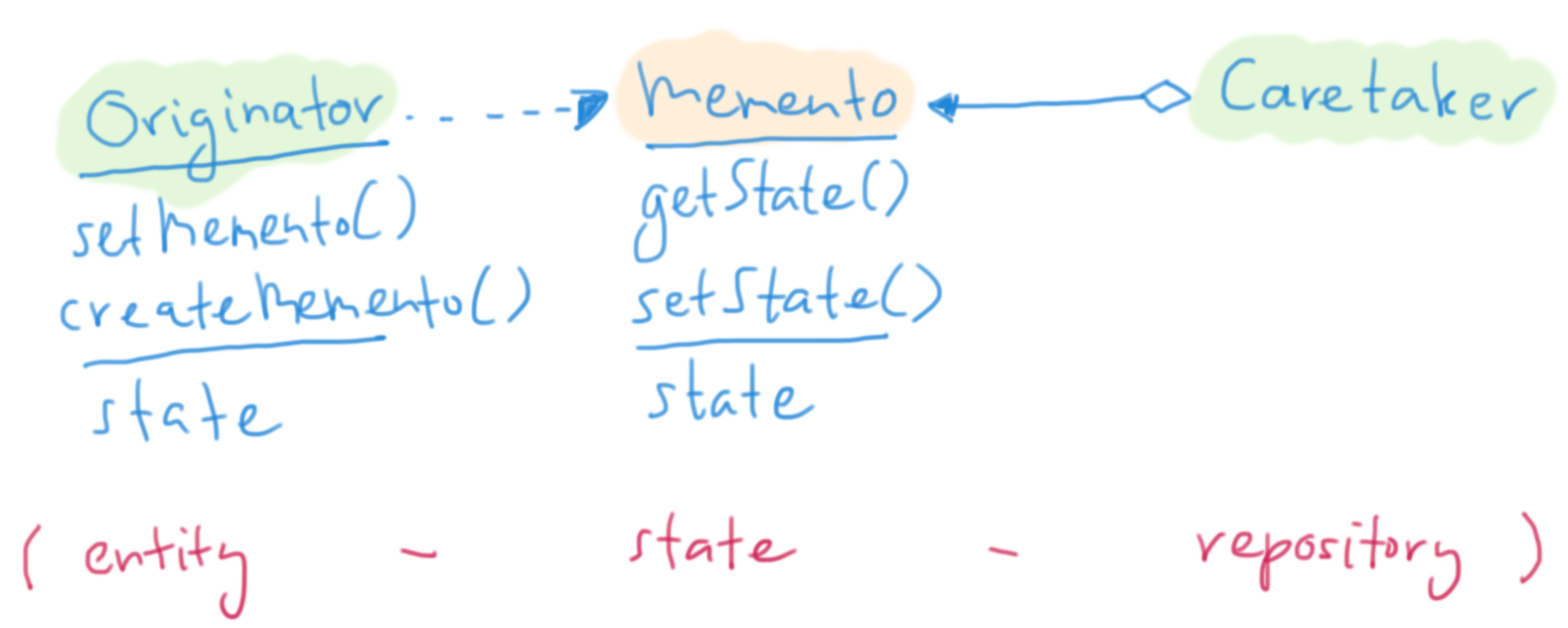
Memento
This reminded me of the Memento pattern from the old "Gang of Four" book. The pattern actually proposes an intermediate object called "memento", with two interfaces: one for the "originator" - the entity in this case - and one for the "caretaker" (the object repository in this case). The caretaker shouldn't deal with the internals of the memento object, the originator does (since it needs to inspect it and take specific values from it when reconstructing its state based on the memento object).
I'm not strictly applying the Memento pattern here, but something very much like it. The rules for me are:
- An entity has a
getState()method which returns an associative array (map) of column name to value, for every given value that needs to end up in the database. This is sometimes a value copied from an attribute, sometimes a derived value, sometimes a constant value. - An entity repository should not inspect any of the values in this state array. It shouldn't have to do any processing before handing the data over to the database.
final class SomeEntity
{
// ...
public function getState(): array
{
return [
'fooColumn' => $this->foo->asString(),
'barColumn' => 'constant value to store in column',
// ...
];
}
}
Since the array returned by getState() is tailor-made for the database table that's going to contain this data, we can feed it directly to something like Doctrine DBAL's Connection object, so we could do something like this:
$state = $entity->getState();
$this->connection->insert(
$this->tableName,
$state
);
Step 3: Implement a method for restoring the object, based on its state
We can get the state of an object as an array, but we can't yet restore it from a state array. So we need to add a fromState() method to the entity first:
final class SomeEntity
{
// ...
private function __construct()
{
}
public static function fromState(array $state): SomeEntity
{
$object = new self();
$object->foo = Foo::fromString($state['fooColumn']);
$object->bar = $state['barColumn'];
// ...
return $object;
}
}
(Optional:) Keep only primitive-type values inside the entity
I'm currently experimenting with keeping only primitive-type values inside the entity. This means that instead of keeping value objects inside the entity, or recreating them in the fromState() method,
- I only store primitive-type values inside the entity, and
- I recreate value objects based on those primitive-type values only when needed:
final class SomeEntity
{
// ...
/**
* @var string
*/
private $foo;
public static function fromState(array $state)
{
$object = new self();
$object->foo = $state['fooColumn']);
// ...
return $object;
}
public function foo(): Foo
{
return Foo::fromString($this->foo);
}
}
This means that within an entity, value objects only exist at the boundaries (as method arguments or return values).
Note that I'm experimenting with this. One thing to be aware of: if the value in fooColumn is invalid according to value object Foo's rules, you will only know this when you call SomeEntity::foo().
Step 4: Implement a repository for dealing with state
Once everything is in place, it'll be very easy to implement a method that stores a new entity in the database, something like:
public function add(SomeEntity $entity): void
{
$data = $entity->getState();
$this->databaseConnection->insert($this->tableName, $data);
}
The update scenario is pretty simple too:
public function update(SomeEntity $entity): void
{
$data = $entity->getState();
$this->databaseConnection->update(
$this->tableName,
$data,
[
'id' => $entity->id()
]
);
}
And the getById(), which uses the fromState() method:
public function getById($id): SomeEntity
{
return SomeEntity::fromState(
$this->databaseConnection->findOne(
$this->tableName,
[
'id' => $id
]
);
);
}
Of course you need to find out if a row was returned from the database and throw an exception if that wasn't the case. And I'd suggest (like I did several times before) to define an interface for the repository as well. But you get the idea: using getState() and fromState() the repository implementation can be very simple.
Some topics for further discussion
As I mentioned, I'm still figuring out if the above is a good approach to object persistence. So far so good! I'd like to discuss a few things now, which may help you decide for yourself.
First, I think it's a big advantage that the mapping of the object's internal data to fields of a database schema happens inside the object that gets mapped. If something changes about the internal structure of the object, the state-related methods can be updated accordingly on the spot. An important advantage to me is that we don't need any special mapping configuration. The mapping is hard-coded, conversion between value objects and database-friendly value types happens inside the *state() methods.
Compared to having, for example, annotations for mapping configuration, we end up with a much more flexible mapping style. With annotations, we configure how a certain object attribute needs to be persisted inside a field in the database. This often makes our objects symmetrical with the database tables that store them. Using the approach described in this article, there's no need for this, in fact, objects can be completely asymmetrical, which matches well with your DDD aspirations (if you have those!).
Since this mapping is something "owned" by me, without any external (or vendor) dependencies, it's okay to write a unit test that verifies the correctness of the behavior of getState() and fromState(). You can test all the subtle aspects of these methods.
$object = // ...;
self::assertEquals(
[
'foo' => 'value'
],
$object->getState()
);
With "object-relational mapping-as-code", we don't need to be afraid of misunderstanding our favorite ORM. We do need to write an integration test for the repository, to verify that an object can indeed be stored in the database and retrieved from it. It could be as simple as this:
$originalObject = // ...;
$repository->add($originalObject);
$reconstructedObject = $repository->getById($originalObject->id());
self::assertEquals($originalObject, $reconstructedObject);
I have also used an approach like this in the past and although I don't think that every project is suited for it, I love how simple it is and I still use it for many projects.
That being said, I still think that the entity would be more "domain purer" if it doesn't know how it's being stored on the database.. If the application is database-centric it isn't a problem of course (I think it is even better in this case), but when I have lots of business logic inside the aggregates, I prefer to let the storage logic be exclusively in the repositories.
What do you think?
I wondering how to implement migrations with this approach. I would like to have some kind of "magic" mechanizm that will keep my entities/model up to date with structure of database. This seems to be easy with doctrine orm approach where usually one entity field is one table field. Here I'm worried about writing one extra character to varchar(25) field and not noticing it.
However, presented it this post idea seems to me "good".
Take a look at TalisORM, which implements this design and also provides an option for managing the schema with Doctrine migrations: https://github.com/matthias...
I've seen TalisORM but I definitely missed that part. Thanks!
This looks like a very interesting concept. There's a lot of stuff I like about it, such as the freedom it gives to modelling a domain. I do take issue with some of its fundamental principles, though!
First off, it's a good thing you pointed out the "small aggregate" thing, because not following that rule would seem to be detrimental to this concept: besides not supporting lazy loading, there's no change tracking. Ergo, the *entire aggregate* would be sent to the database on each persist operation, even if only a single field has changed. This could be mediated by comparing the final state with the original and only persisting the changed fields, so I won't hold it against the concept itself ;)
Something I have more trouble with, is how the entity gets coupled to the persistence mechanism, and most likely to the ORM itself. It may be just the TalisORM implementation, but having my domain entities implement an interface that's owned by the ORM seems like little gain over extending a base class from an active-record-ish tool. (There's a lot less magic, which is nice, but coupling to ORMs is not what I had in mind for my entities...)
I suppose it all comes down to an architectural decision: are we more willing to allow a scary-looking ORM to inspect and even alter our carefully designed internal states, or do we allow ourselves to be coupled to the persistence mechanisms from within the entity?
When taking medicine as analogy, we might put it like this; do we trust our doctor to examine our internal state, or would we prefer to be hooked on to the life-sustaining machine all the time? In case of a shady doctor, I can understand the latter choice. But wouldn't improving the medicinal standards be an even better option?
I've been thinking about something like this for a while. Glad to see someone else on the same path. My focus was more on serialization than persistence, but they're VERY similar concepts. The hard part is that different serialization types can need some metadata that others don't inherantly understand. And "versioning" of persistence and serialization can be a thing to keep in mind too (more for serialization that persistence, though).
Hi! Great post. How would you deal with a has-many relationships between entities in the aggregate? For example, an order that has multiple order items.
1. Would you make a nested array? For example:
[
'foo' => 'bar',
'some_children' => [
[ 'prop_of_child' => 1],
[ 'prop_of_child' => 2]
]
]
2. Where would you handle the children state (getState and setState)? Should those methods be implemented in the children objects, and be called from the parent getState and setState methods? For example:
public static function fromState(array $state)
{
$object = new self();
$object->foo = $state['fooColumn']);
// assuming a has-one relationship
$object->child = Child.fromState($state['mychild']);
// ...
return $object;
}
Good question, I may have to blog about that later. For now you could take a look at the examples in the tests directory of TalisORM: https://github.com/matthias...
I tried something similar, with multiple static constructors (entity can be constructed not only from database) and some magic behind (like automatic translation object/bool to corresponding database data type) and some potential issues. Your solution is elegant, simpler and doesn't have that issues. Good job.
Oh, that's great to hear! Did you see https://github.com/matthias... ?
What an interesting approach! Since it's been a few months, I would love to know how this has worked out for you in retrospect. In this article, you mention:Note that I'm experimenting with this. One thing to be aware of: if the value in fooColumn is invalid according to value object Foo's rules, you will only know this when you call SomeEntity::foo().Why wouldn't the entity's method
::fromState()immediately attempt to instantiate the value objects and set them as the instance properties? That would enforce your invariants immediately, instead of waiting until someone called a getter to see if an exception is thrown.Put another way, it seems that using your proposed approach would make it far easier to map value objects to database values, and vice versa. Why then only store primitive values as instance properties? How is that a superior design? I think I'm overlooking something! :)Hey, I don't know if I've answered this before because I have a dejà vu about this. But anyway.The thing is, you shouldn't need to enforce invariants when the data is coming from the database. However, I agree it would be useful to get that feedback. But you'll get the feedback as soon as you start using it anyway, since then you'll be reconstructing those value objects. Depending on how trustworthy your database is, if anything, fromState() offers you a lot more flexibility to deal with ambiguous data that you don't really care about.In general, I'm convinced that
fromState()andgetState()is a really nice option to go ORMless. One alternative you might try is writing the state mapping in a closure, and binding it to the entity object from inside the repository class. Not sure if that is really worth it though.Thanks as always for an excellent response! Your input is awesome, sorry if I've made you repeat yourself
No problem, thanks!
One downside I see of throwing away Doctrine is that we can't use lazy
loading anymore. Do you always fetch the whole aggregate including relations? I imagine anyway you just need to fetch the aggregate for write operations.
Indeed; I do, and it makes sense. But only if you apply the DDD rule to keep your aggregates small. Relations are not and don't have to be loaded eagerly, because they are als modelled using the DDD rule to link aggregates by their ID only.
I did really enjoy it this article... I have always the feeling that every developer jumps into an ORM just because everyone does.
Now, I'm trying to think if this approach can scale for large projects, and what kind of caveats we should take... like security, sql injection, etc. So, if you have any update about the related project using this, it would be good to ear from you.
Anyway, thanks for sharing!
Thanks. A couple of months later I'm very happy. We start having integration tests for every repository, which makes the need for functional tests in some areas less urgent.
One disadvantage discovered so far is that knowledge about the meaning of certain columns and their data starts ending up being copied to different parts of the code base. Not that much, so far, but it's happening in some places. This is in part to be attributed to the database-centricness of the application, as well as the age of the database.
How does that knowledge-copying manifest itself?
By the way, isn't the problem worse with Doctrine, where an entity knows not just what a column "means" to the domain, but is also tied to a technical implementation as far as the datatype of an instance property is concerned?
Well, for instance, a column is somewhat like an enum (e.g. values can be 1, 2 or 3). The knowledge what these values mean, and what maybe some other column's value means given that first value is for instance 2, ends up in multiple places. So that would be the point where you could maybe extract some logic in a shared class (like a value object).
Yeah, considering our experiences so far, Doctrine would be worse :)
Nice and simple idea, I like it!I've just discovered that the DBAL Connection class provides a
projectmethod which is perfect for applying a transformation on the fetched rows prior to returning it.Take a look at the following gist: https://gist.github.com/gqu...That's pretty usefull IMO to avoid loading a whole collection of database records in memory before transforming it (not sure if this is famous, that's why I'm posting it here).Thanks, nice tip!
I could not like this idea more. At my company we recently come up with similar approach. Acctualy it is not really ours, I think the world just works this way :) We are experimenting with ES approach. Early on we noticed our domain code tends to get coupled with ES framework. For example, way of persisting data affects domain models shape. The idea is to split aggregate behavior and state to dedicated class. So aggregate itself does not care if it is event sourced or not - it get reconstitiuted from given state object (as you propossed). The problem how you get the state object is up to your infrastructure choices as long as it implements domain interface (IoC of some kind).
Thank you for sharing
Really interesting idea. The reconstruction is similar as in Event Sourcing, though you are "deserializing" the aggregate instead of the events. Thanks for sharing.
Another question: You mentioned the UserInterface. Will this be another topic indeed? That's something that bothers me right now, so I would be very interested in your thoughts.
Hi, I'm not sure if/when I'll write about the user interface. The issue is often, you have a nice domain model, but it doesn't fit well with the user interface as it's too CRUD-dy.
I've got some minor itches when reading this. It probably all depends on the use case you are working on. You must really know what you've gotten yourself into when doing something like this. The implications are too many to take account for. For instance, how to refactor the entity listeners we have in a certain project. Or our doctrineBridgeBundle. Or our security layer with data encryption by guards and such. I could go on, but you get my point. I think ormless is good for small projects or as you said projects that really need a better model structure/way of handling things. Good write as always Mattie.
Thanks for joining the discussion! Yes, I agree: the more logic you have in between your repository and your database, the less useful this approach becomes. The above works really well if your database is really just a simple place to store your data. By the way, events work well with this too, if you record them inside the entities, and dispatch them later on.
Cool, i guess i build something similar as a generator. Can you check it out, that i have implemented right? Repo: https://github.com/shyim/Da..., Example generated code from a mysql table: https://gist.github.com/shy...
A probably "unusual" feedback here. I make a living working with WordPress. Me, and we at our company, try to write modern code around WordPress. One of the major problems we fight is that WordPress does not have any ORM, nor any decent DB abstraction that goes over the very basics. In this situation we were forced to think ORMless. You won't be surprised that I come up with a similar approach: all my entities have
toArray()and afromArray()method. No inheritance involved, just these 2 methods implemented from an interface. The entity is then accompanied with a repository, that takes care of storing the array created by entity in the DB. Because WP has its own tables, whose design we don't control, and its own functions to store specifc kind of data, the repository very often do something different than just saving the array as-is in the DB, but calls WordPress-specific methods to store data where it belongs (e.g. post data will be saved withwp_update_post(), meta data withupdate_post_meta()and so on). This logic needs, of course, to be reversed when unserializing the entity from DB. Because there's a specular logic between the serialization and the unserialization, and because the serialization happen in the repository, I put the unserialization logic in the repository as well. This unserialization logic re-creates the array in the same way it was passed by the entity and then pass it to the entityfromArray()method. This ensures compatibility betwen our code and WordPress, leaving us free to design entities according to our model. This as worked very well, and I always saw this as an acceptable trade-off for a system missing of a more advanced persistence abstraction. I'm somehow glad to see that this approach is considered as a design choice and not as enforced choice.Thanks for sharing this. In the project where I introduced this style, the issue is mainly that there in many cases there were no proper models. The design described in this article enables very nice design techniques, while still being compatible with the database behind it. In fact, I like how everything becomes more explicit (unless when using an ORM with automatic mapping).
I really like the idea, but I think that we would have to use a lot of boilerplate code to map recurring fields to our object. Remember getId(), new \DateTime($state['dateColumn']), and so on. If you include relationships, you'll end up with Doctrine functionality very quickly.
By the way: When I instantiate an entity ( with ::fromState() ) and need relations to other entities, I get a responsibility problem again: In this case the entity has to retrieve a "foreign" repository to load the related state. We are very close to a not-so-good God-Object - per Entity.
Agreed, that's why I mentioned aggregate design principles: relations shouldn't be loaded, they should be kept only by ID, so some other object can fetch the actual objects if needed.
The boilerplate code may be a bit of an issue, so that's why I've been experimenting with only primitive-type values inside the entitiy's attributes. Any getter may return a re-instantiated value object based on those primitive-type values.
Cool idea! But I have a question. In your last example, what if original object goes out of sync with reconstructed object? ORM's use identity map to make sure this does not happen. I guess repository could have an identity map as well. Do you agree?
For people who do not know this pattern, identity map according to Martin Fowler: https://martinfowler.com/ea...
This could be an issue, for sure, but it doesn't always have to be (at least, in my current project, it isn't). I agree about using an identity map (nothing more than a really simple map which the repository could use to look up if it has already loaded an object with a certain ID.
The State object seems to approach something like an Atlas Record. (Atlas is a data mapper for the persistence model, not the domain model.) Cf. http://atlasphp.io and especially http://atlasphp.io/mapper/2...
Thanks for sharing, Paul!
Interesting, I used the same approach once to refactor an app which uses Active Record so to isolate it I created domain entities in the domain layer and in the infrastructure layer I added a domain module which have classes that inherent from domain entities there I implemented methods that deals with the state I call it snapshot instead of getState or momento and static factories like you do.
For the transaction I used decorator pattern to decorate Application services.
Sounds a lot like it; however, I wouldn't recommend extending the entity, which would require widening of scope (protected properties and methods) and instantiating becomes impossible without knowing which infrastructure class to use...
Very interesting approach, thanks for sharing!
Having the mapping in the entity feels a little bit not-DDD to me. Somewhere, I feel like an Entity shouldn't need to know about how it's going to be stored, but maybe that's not such a big problem. I wish there was a way to let only repositories interact with the getState() method.
How would/do you deal with entities that use incremental IDs? What about UUIDs?
You need to pass some values to an entity constructor, right? So, instead of passing some values separately, you pass a state object reference. In addition, you can think of a constructor and a factory method to be the same thing (with factory method being more flexible due to being able to return values, ex. entity instance + validation results). I think there is nothing non-DDD here.
In my implementation, the constructor has no arguments, so I can construct an empty instance in those
fromState()methods. But of course, creating an entity requires some values to be passed in, so therefore I add one or more static methods a.k.a. named constructors.I had the same feeling, but I consider
getState()andfromState()not part of the "modelled interface". That way, the entities can be even more DDD than ever (you don't need to comply to any ORM-enforced thing like carrying references to other objects or using special collection types).Incremental IDs make no real difference. Except, there's no way to set the ID after persisting (unless you add another "internal" method, e.g.setId()) to the object. The solution would be to set the ID in the state array, and recreate the entity by passing this modified array tofromState().'Recreate entity' sounds ugly. What about
?
I understand your concern, although personally I don't think it's a really big deal. Conceptually, it's correct to recreate based on a modified state array, because that array already represents the data as it is in the database (including now the auto-incremented ID).I don't really like the two faces of
fromState(). It may help you prevent reference issues. I know that an ORM like Doctrine has to care about an object with the same ID to have the same reference. With the approach describes in this article, this isn't as important anymore (since you're not keeping object references at all, but instead link between entities only by their ID). I realize now that I almost never rely on an object to be the exact same object. As long as it behaves in the same way, it should be fine.I really like your solution and I also think it is much better like this than with using annotations. I only see one problem though with your idea: the entities/value objects are now tied to one database (probably a relational one) and might not support another one with very different semantics (for instance Mongo DB for caching purposes). So I would be interested how you instantiate your objects from a cache? Would you create another static method like fromCacheState?
What I do in a project of mine needs much more effort but more flexible in my opinion: I create a Factory for each of my objects and I instantiate them by using these Factories. If I need multiple ways of persistence then I create multiple Factory implementations. Furthermore, when I want to store my objects, I map the object properties to database fields in a Model class. For instance, if I want to store my objects in MySQL and Redis then I create a MySqlModel and a RedisModel for each tables/documents/keys I have (I developed an "ORM" kind of program for relational databases that supports this style).
I know my approach is not perfect because it needs too much effort and I have to create a getter for each field (which I hate). So I hope that I can use a more convenient method once which is as flexible as the current solution. But I'll never use annotations in the future! :)
I'd definitely store the same data in the cache as I do in the database. That way you can actually reuse
getState()andfromState().Also, yes, state-related code will be tightly coupled to the database you use. I find that it's not an issue. If you're writing reusable library code or something, it will be an issue, but your project probably uses one database for every type of object, so then there's no issue.
Yes it's very much going to depend on the project. It's pragmatic, though for my tastes too coupled and I would prefer a companion class to map to/from state, which is a pattern I'm using, rather than an ORM.
Though it breaks down as soon as the queries are more complicated, and I realise why Doctrine is so damn complicated :)
Well, for me this works great, because in the current project we always separate write from read model, so this state stuff doesn't influence the query side.
If you don't want to have database stuff in your class, I find that you end up with a lot of getters on the entity and that the mapping code is where the coupling is (it will be coupled to the internals of the entity, but it will be outside the entity, which isn't very convenient if you're making changes to the entity's internals).
Very interesting read, thanks for writing it.There were few things that caught my attention though, like this part for example: Since the array returned by getState() is tailor-made for the database table that's going to contain this data, we can feed it directly to something like Doctrine DBAL's Connection objectDoes this mean that entity should contain DB-specific logic, such as converting values into appropriate SQL column types or dealing with
MongoDB\BSON\UTCDateTimeif MongoDB is used as a storage?Very nice article, thank you!
I think combining this approach with NoSQL storage is really powerful because it helps to mitigate Object-relational impedance mismatch problems.
Moreover, storing whole JSON as-is allows to handle migration in getState and fromState method. For example add extra field __version if needed and check it in fromState. Also deployment does not require permissions to change database structure.
I have used similar Memento Pattern approach to store entities. Because client had a RDBMS I could not use MongoDB or similar storage. I stored whole entity state as a JSON in one column and that's it. Of course one extra column for id.
In some cases I needed to fetch entities based on some attribute. For specific performance reasons I added extra columns when entity was saved. But actually it is not needed because databases support JSON types and functions to do search in JSON fields (MySQL, PostgreSQL, SQLite, Informix). Informix even has a Mongo compatible interface (JSON Wire Listener) for integrating Informix into applications that require MongoDB.
In the *state methods we work with simple PHP scalars only. In MySqlUserRepositiry translate it to MySQL syntax, in MongoDbUserRepository to mongo syntax, in RedisUserRepository to redis one. All of them implement UserRepositoryInterface with add, getById and other 'collection's' methods.
The goal should be to return only primitive-type values in
getState(). I didn't have this use case, but if the MongoDB driver really needs objects, you'd have to pass them of course.I've been using the league/fractal package a lot for transforming entities to json responses. Maybe a similar approach could be used here as well. But then you're basically mapping again...
Thanks for this inspiring article! I would also prefer to hardcode the mapping inside the object. Maybe only for larger objects I would create an custom (per entity) entity-state object with ArrayAccess.
Thanks for letting me know!